5 Reasons You Should Be Using LakeFlow Jobs as Your Default Orchestrator
I recently saw a business case where their external orchestator accounted for nearly 30% of their total Databricks job costs. That's when it hit me: we're often paying a premium for complexity we don't need.
From a FinOps perspective, the simplest move is to migrate orchestration to native Databricks, which can significantly cut costs with minimal disruption.
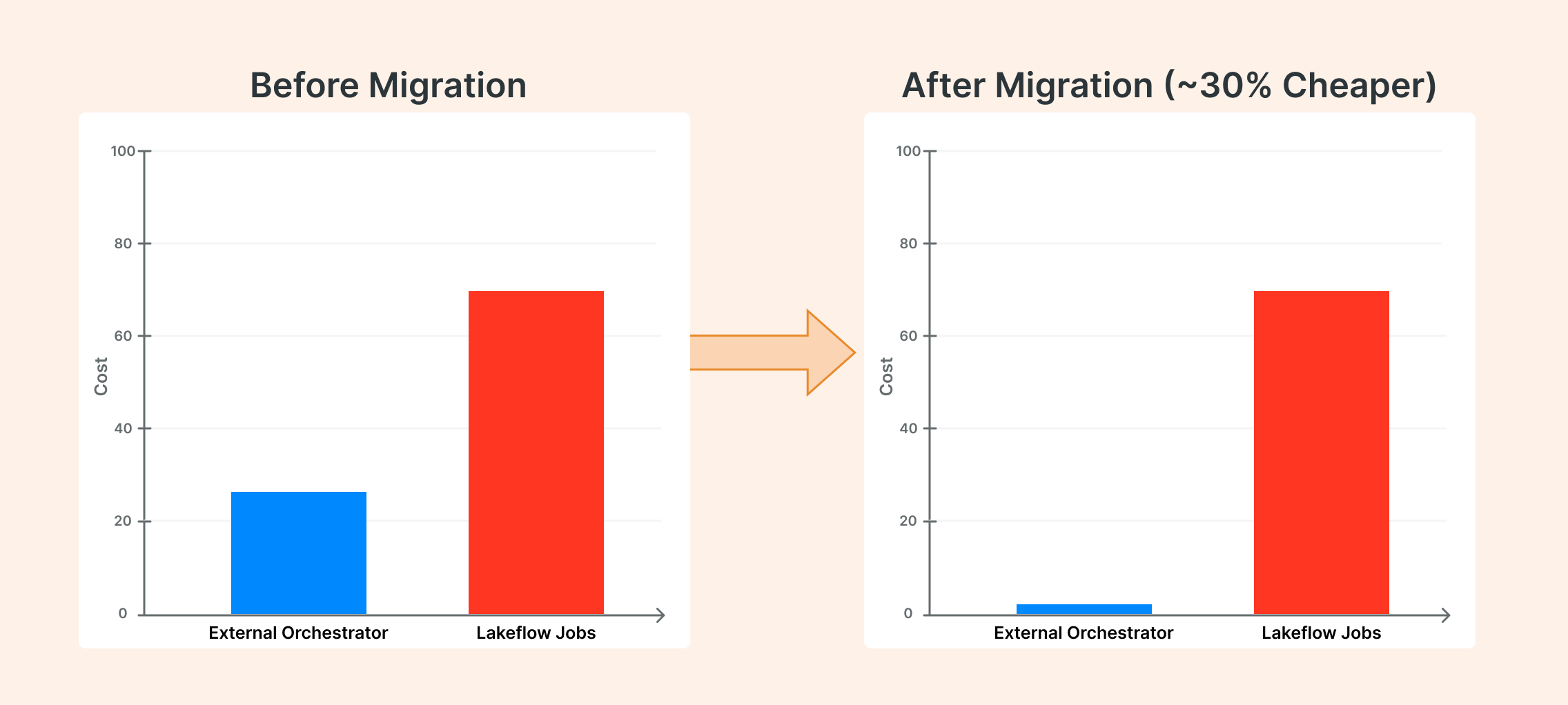
I’m still wondering why external orchestrators remain so popular for Databricks workloads, in the meantime, here are 5 reasons why LakeFlow Jobs should be your go-to orchestration layer:
1. Infrastructure as Code (IaC) that actually works
Many external orchestrators make “configuration as code” awkward. Databricks Asset Bundles uses intuitive YAML, making versioning and configuration review straightforward. You can also mix approaches: configure in the UI and keep the YAML in source control. Deploy via CLI or UI, your choice.
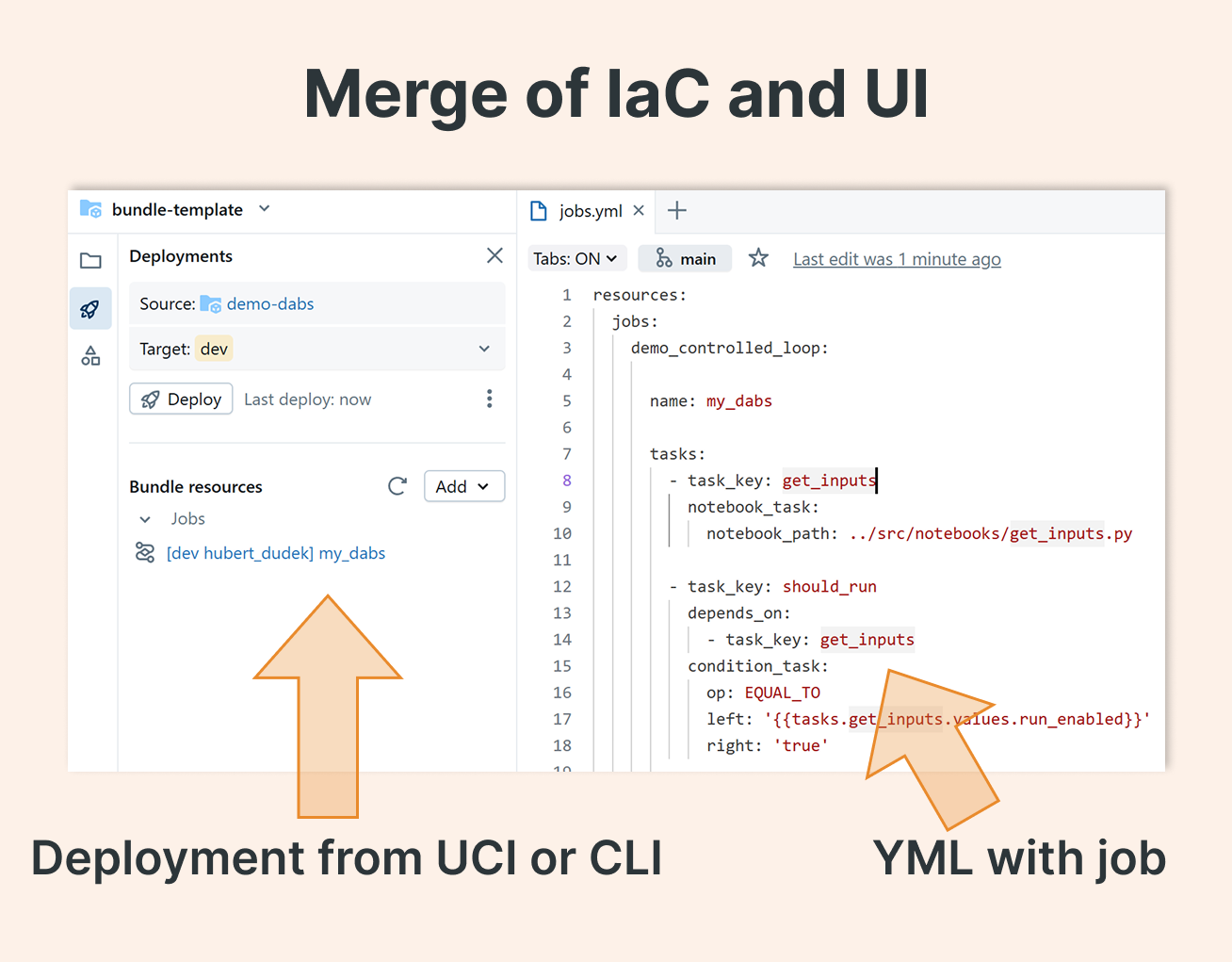
If you prefer to build via a low-code UI, you can easily export to YML later.
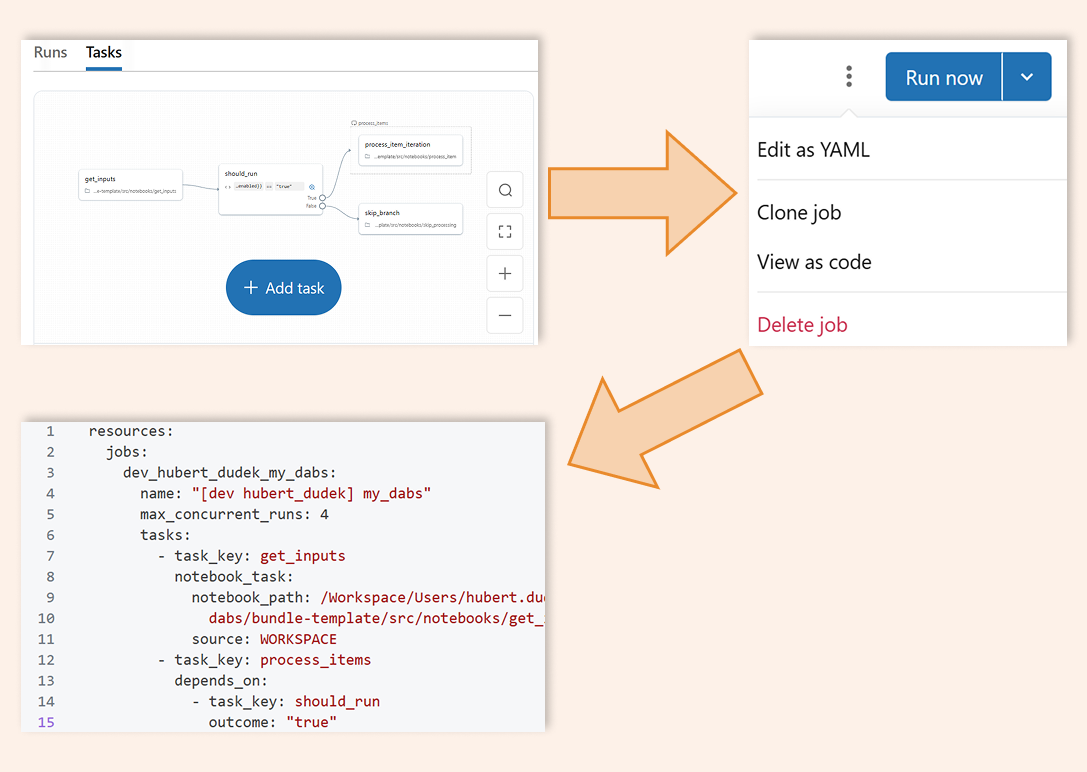
2. Built-In Conditional Logic
Parameterization and conditional branching are built into LakeFlow Jobs, so you can adapt job behavior based on runtime inputs or prior task results without bolting on extra tooling.

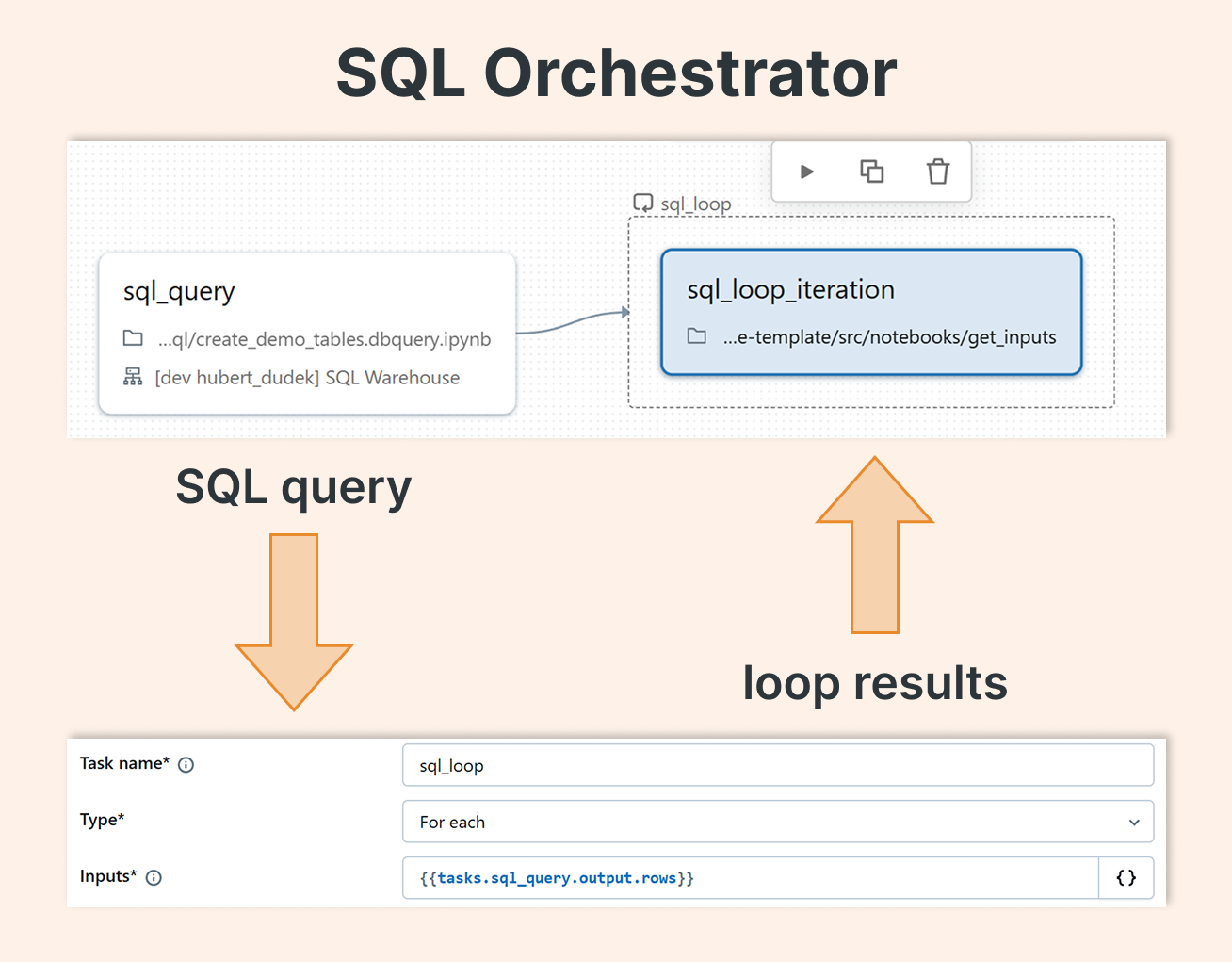
3. SQL‑Driven Orchestration
One of my favorite improvements is the ability to use the result of a SQL SELECT to orchestrate downstream steps. This enables data‑driven decisions right inside the orchestration layer.
4. Native ecosystem integration
LakeFlow Jobs can leverage the complete Databricks ecosystem. Thanks to Lakehouse Federation and Unity Catalog, you get flexible connectivity and governance across sources. Need to orchestrate an ingest from Amazon S3 while running in Azure? No problem, the platform makes cross‑cloud patterns practical.
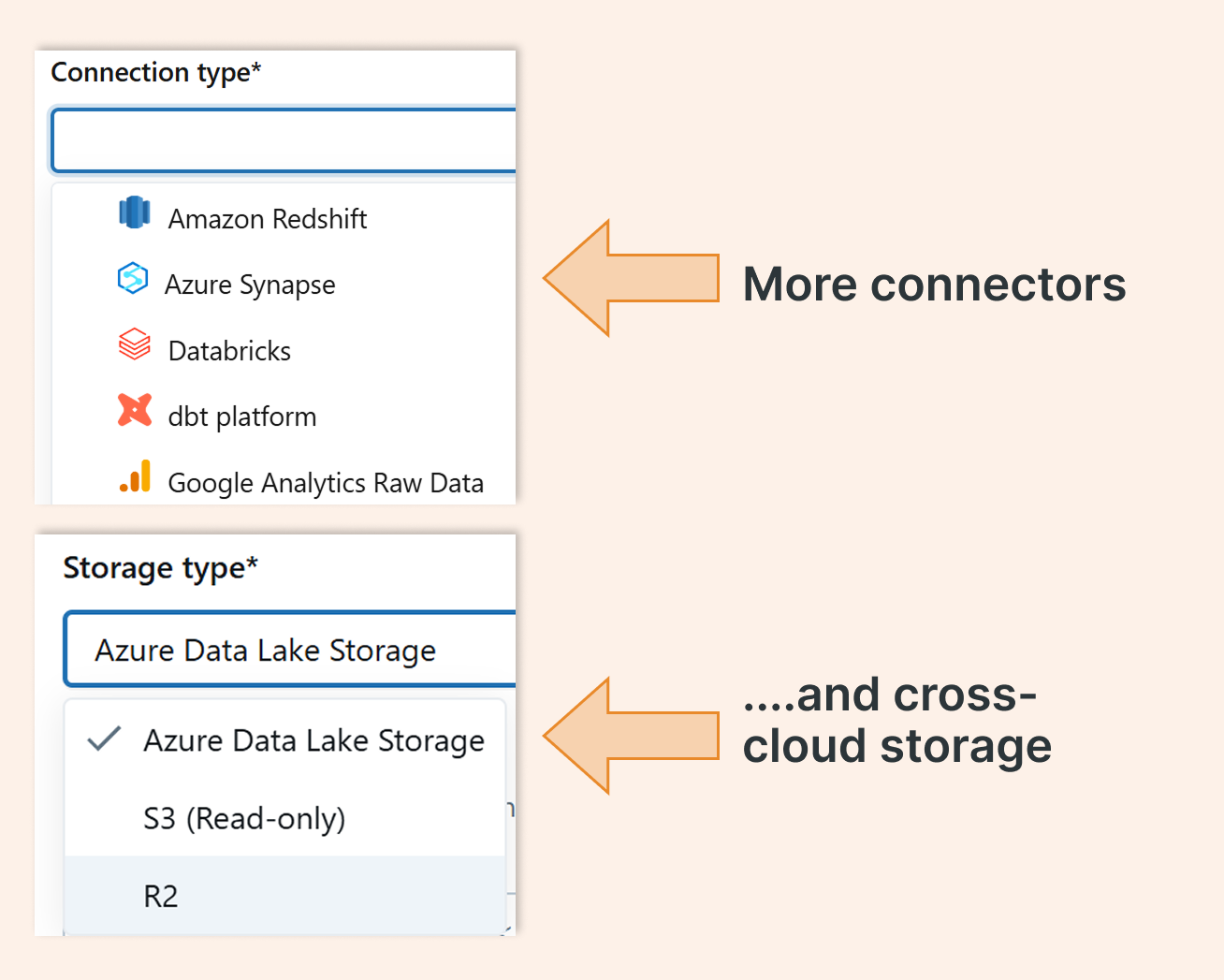
5. Rapid feature development
We’re seeing rapid iteration: task-level re‑runs, backfilling, and more features landing regularl, making native orchestration more capable every week.
Bottom line: If cost and simplicity matter (and they usually do), moving from external orchestrators to LakeFlow Jobs is often the fastest way to improve your Databricks ROI while simplifying your stack.