Lakeflow Connect Free Tier: $35/Day Back in Your Budget
Most data teams don't have an ingestion problem. They have a cost and complexity problem, and their ETL stack is where it lives.
For years, moving operational data from disparate silos into a governed analytical environment meant stitching together third-party tools, maintaining brittle scripts, and paying a "data movement tax" that had nothing to do with the value you were actually getting. On March 18th, 2026, Databricks changed the equation.
Lakeflow Connect's permanent free tier provides every Azure Databricks workspace 100 DBUs per day at no cost — enough to ingest approximately 100 million records per day. For most mid-market teams, that's the entire ingestion workload, covered.
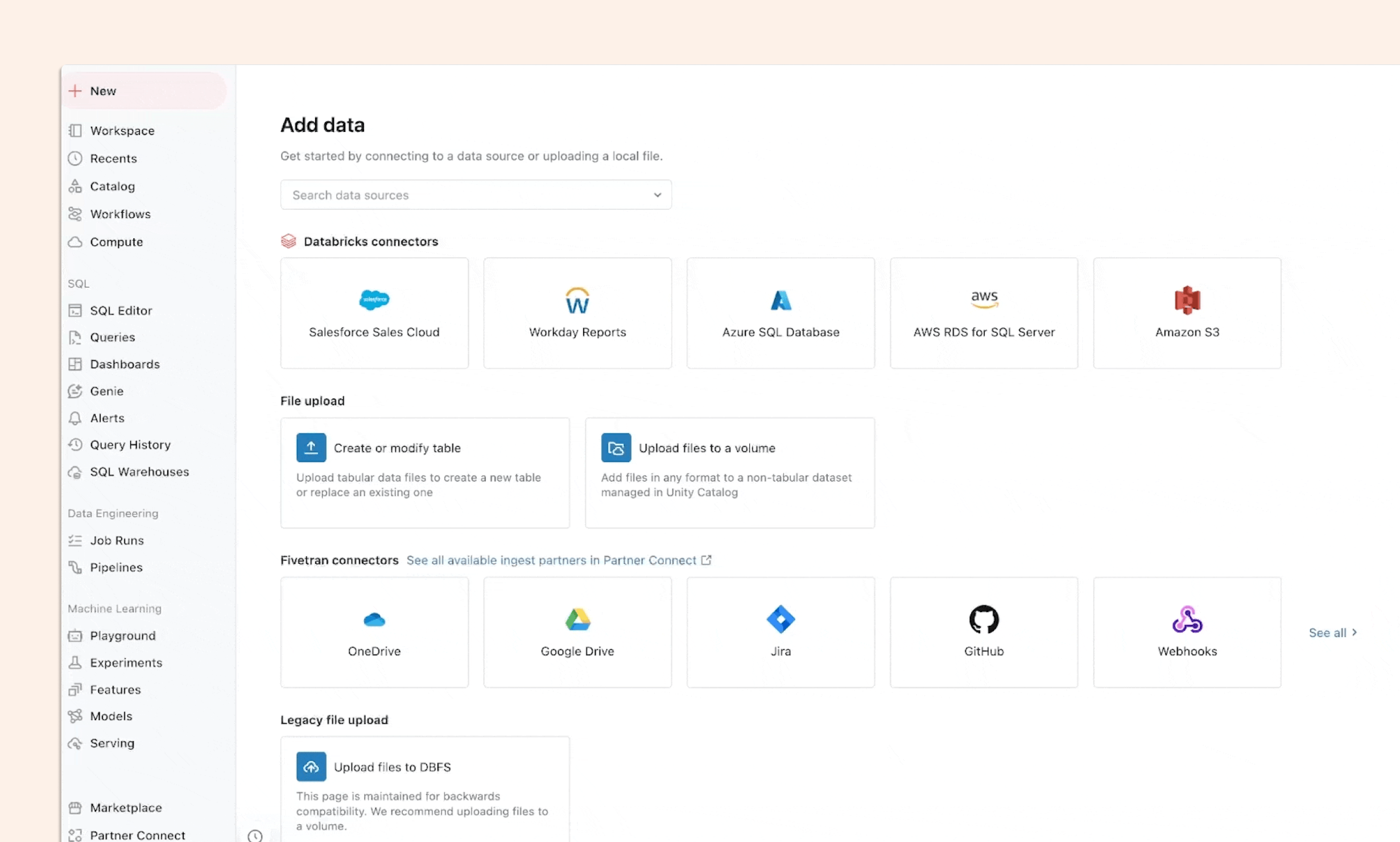
01. The Strategic Imperative of Native Data Ingestion
A proliferation of data across various cloud-based services and on-premises systems characterizes the contemporary enterprise landscape. Whether it is customer relationship management (CRM) data in Salesforce, human capital management (HCM) records in Workday, or transactional logs in SQL Server, the value of this information is significantly diminished when it remains isolated.
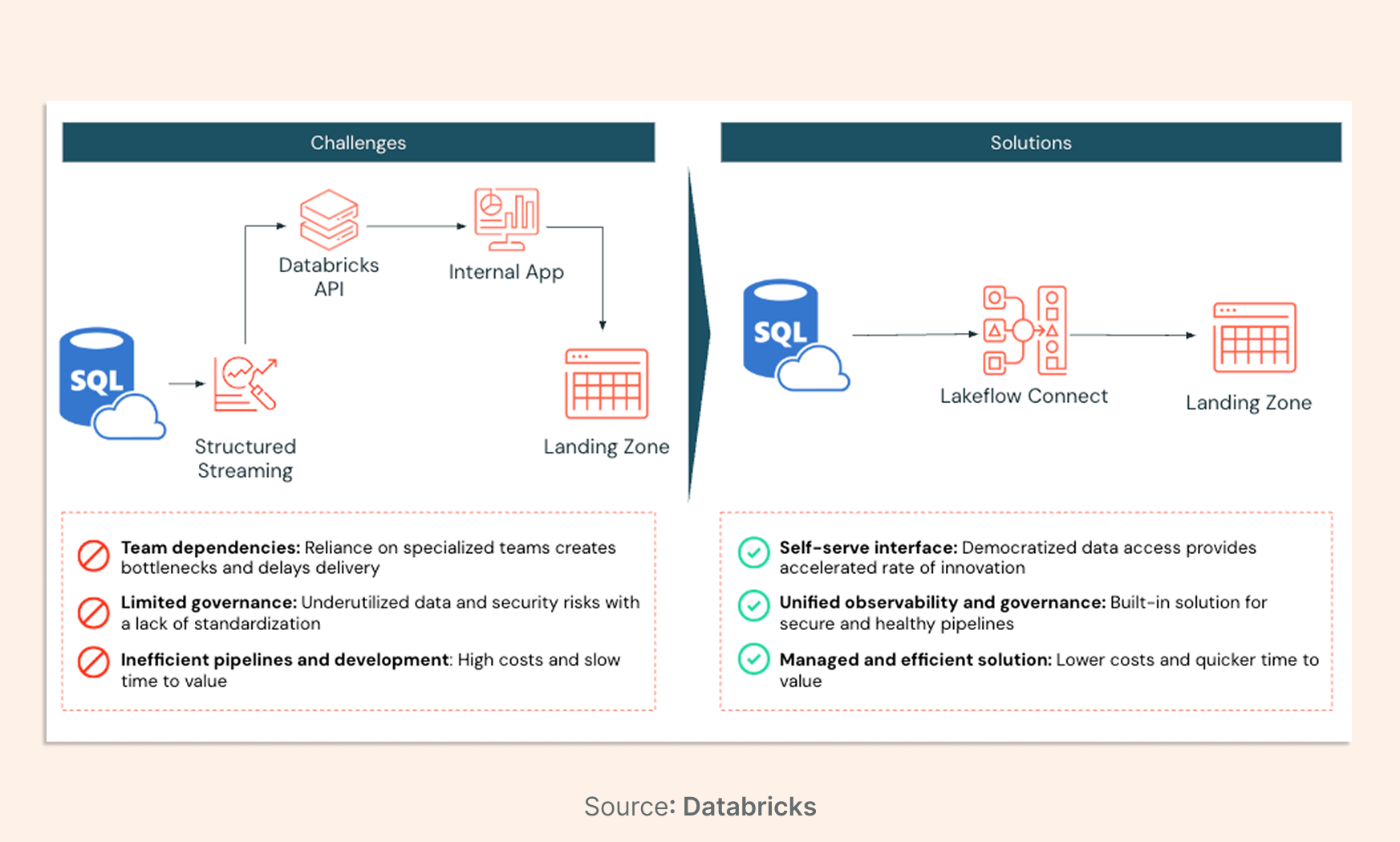
Native ingestion through Lakeflow Connect represents a move away from the "data movement tax" that has long characterized the industry, where costs were often decoupled from the actual value derived from the data. By integrating ingestion directly into the Databricks Data Intelligence Platform, Azure Databricks provides a seamless path from raw data capture to AI-driven insights, ensuring governance, lineage, and observability are baked into the pipeline from inception.
The architectural advantages of this native approach are manifold. Unlike third-party tools that operate outside the lakehouse security boundary, Lakeflow Connect operates within the workspace, leveraging Azure-native networking such as Private Link and VNet peering to ensure secure data transit.
Furthermore, the performance benefits are substantial: organizations using Lakeflow have reported building production-ready pipelines up to 25times faster and reducing ETL costs by up to 83%. This efficiency is driven by serverless compute, which eliminates the need for manual cluster configuration and ensures organizations pay only for the resources they consume during ingestion.
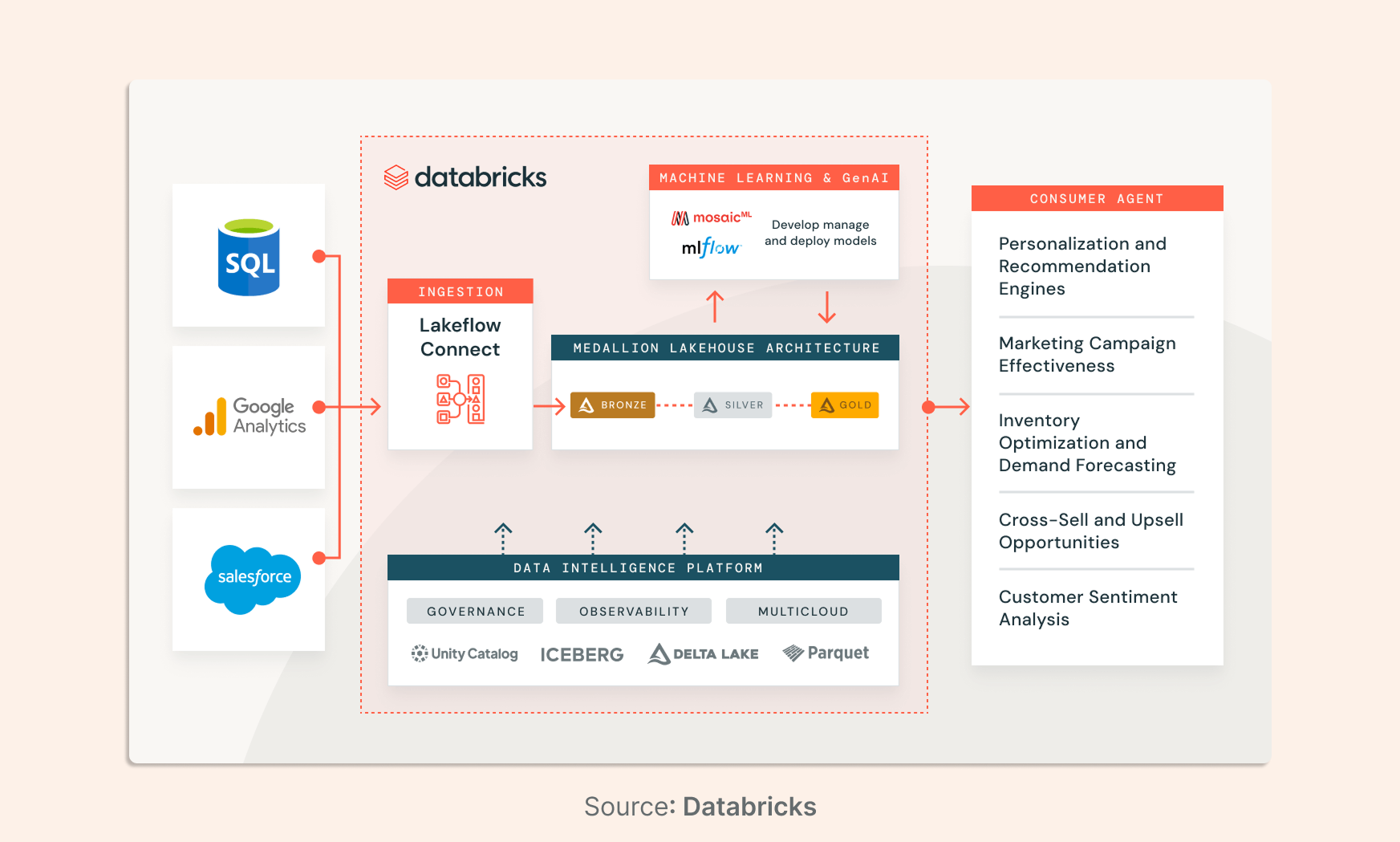
02. The Technical Foundation of Lakeflow Connect Architecture
The Lakeflow Connect framework is built on a modular architecture designed to handle the distinct requirements of SaaS APIs and relational database change logs. At its core, the system uses "Managed Connectors" that abstract away the complexities of source-specific authentication, rate limiting, pagination, and schema evolution.
These connectors are divided into two primary categories based on their underlying operational mechanism: A) SaaS connectors and B) Database connectors
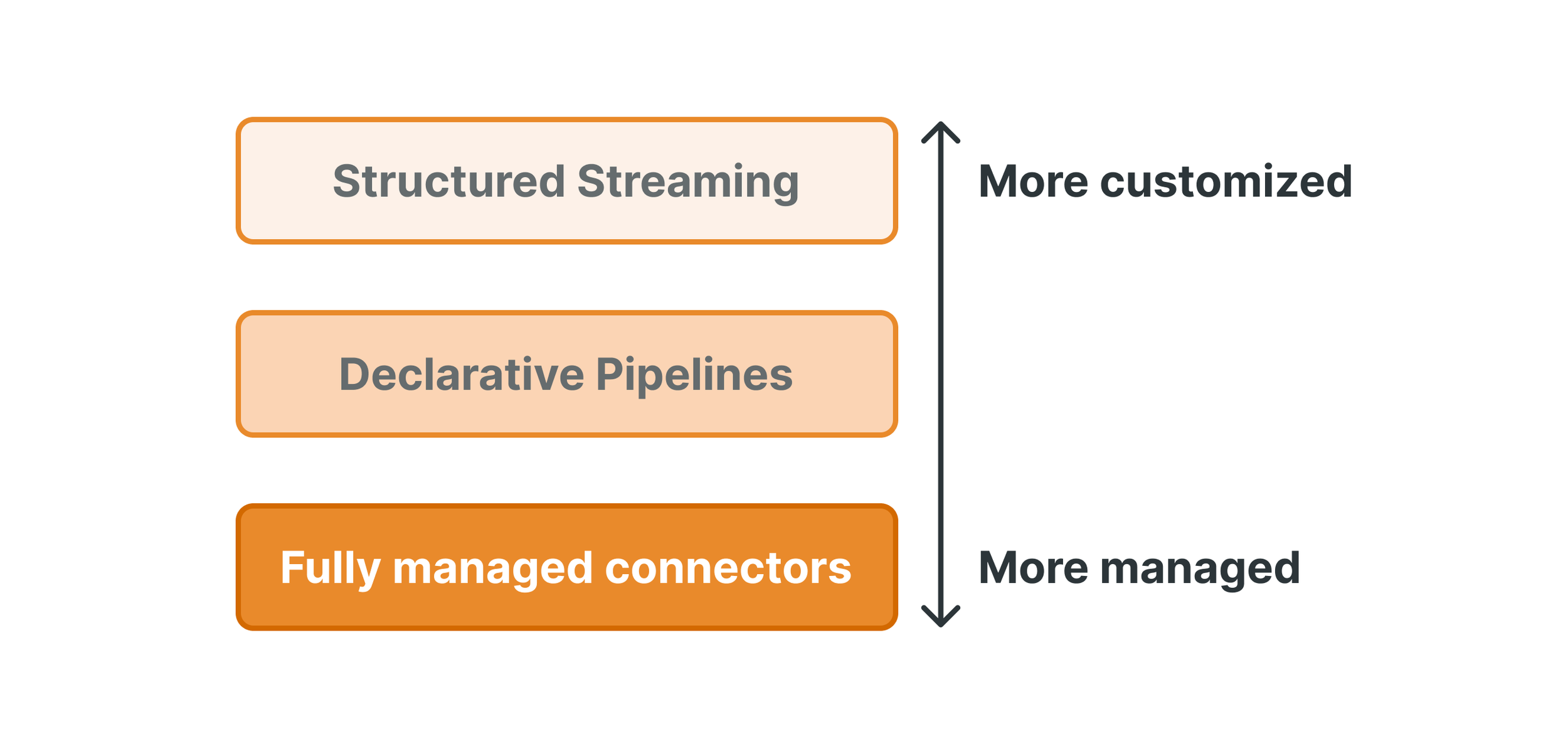
A. SaaS Connector Mechanisms and Serverless Execution
SaaS connectors are designed to interact with the web-based APIs of applications such as Salesforce, ServiceNow, and Google Analytics. These connectors operate entirely on serverless infrastructure, meaning that Azure Databricks manages the underlying virtual machines, scaling, and lifecycle of the compute resources. This is particularly useful for SaaS sources, as API-based extraction is often constrained by the source system's rate limits rather than by the destination's raw compute power.
The serverless nature of these pipelines ensures high availability and resilience. If a sync fails due to a transient network error or an API timeout at the source, Lakeflow Connect automatically handles retries and manages the checkpointing required to resume without duplicating data. Furthermore, because these pipelines write directly to streaming tables, data is available for downstream consumption almost immediately after extraction.
B. Relational Database Mirroring and Ingestion Gateways
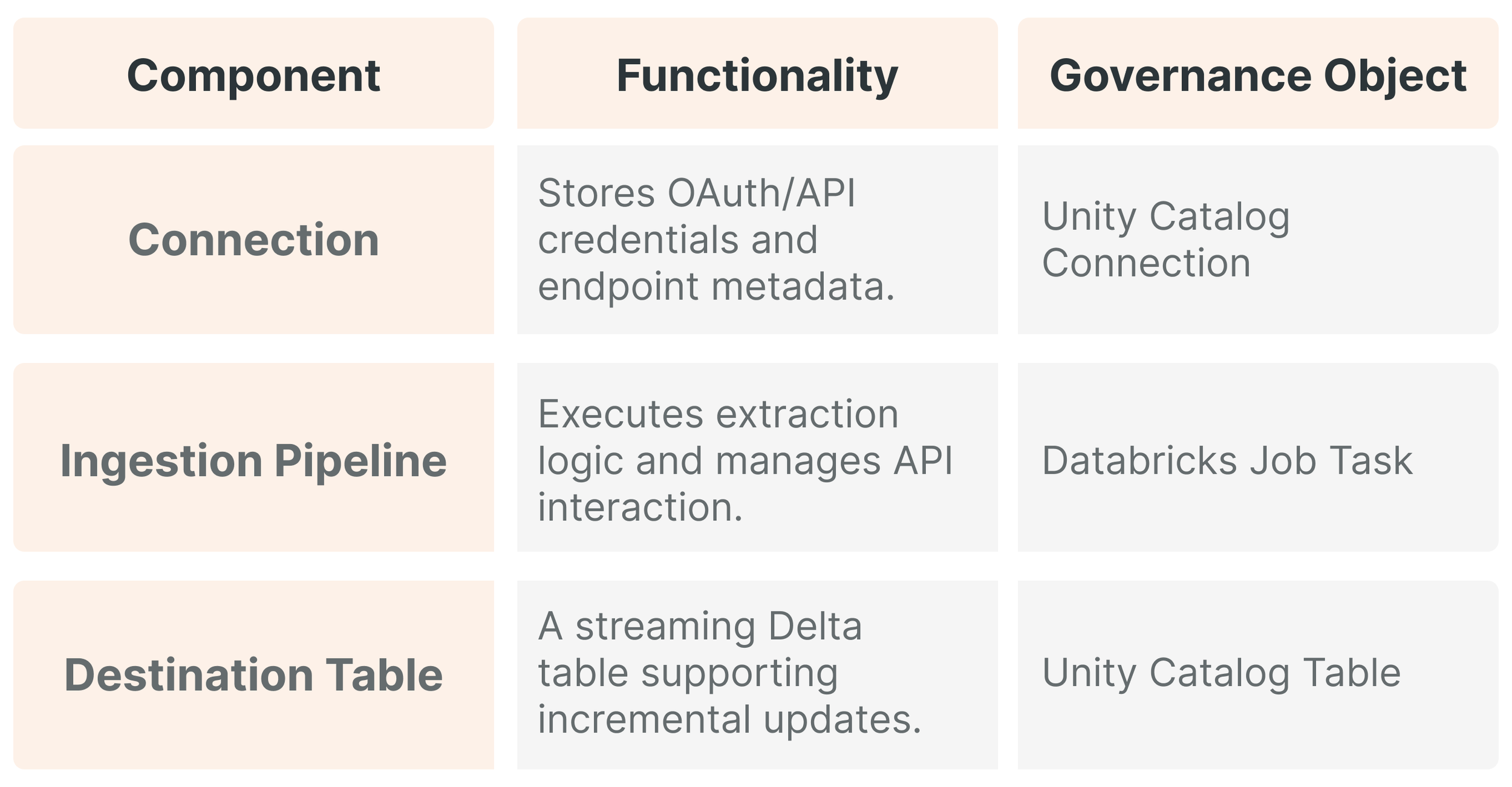
Ingesting data from relational databases requires a more sophisticated approach involving an Ingestion Gateway and Staging Storage. The gateway monitors the source database and continuously changes logs (e.g., SQL Server Transaction Logs) to prevent data loss. This gateway can run in classic compute mode, allowing it to reside within a customer's specific VNet to facilitate secure communication via Private Link or Azure ExpressRoute. The gateway extracts snapshots and changes data, writing it to a temporary staging volume in Unity Catalog.
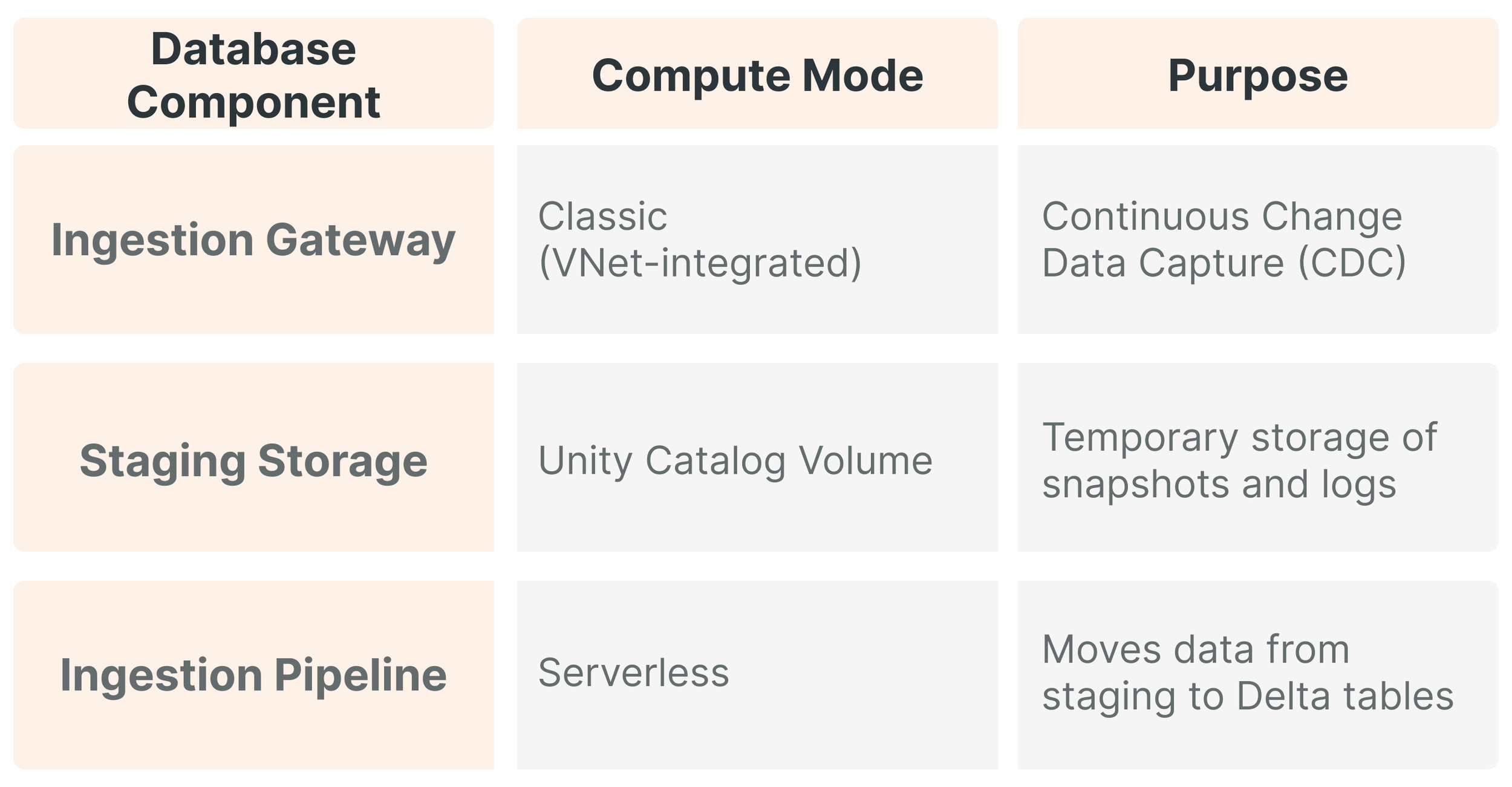
This decoupled architecture allows a gateway to capture changes from a mission-critical SQL Server database continuously. At the same time, the final ingestion pipeline runs on a schedule (e.g., hourly) to refresh the "Bronze" layer, thereby optimizing DBU consumption.
03. An Economic Analysis of the 100 DBU Free Tier
The 100 free DBUs per day per workspace is a central pillar of the March 2026 announcement.By providing this allocation, Databricks removes financial friction for most small-to-medium ingestion workloads.
Understanding DBU Consumption and Efficiency
A Databricks Unit (DBU) is a normalized measure of processing capability per hour. In the context of Lakeflow Connect, managed connectors are priced at a flat rate (currently $0.35 per DBU on the Premium tier). The 100 DBU daily credit equates to a direct subsidy of $35.00 per workspace per day. Databricks estimates that 100 DBUs will enable the ingestion of approximately 100 million records per day.
This benefit translates to an approximate saving of $12,775 USD per year per workspace. In large organizations operating with, for example, 20 active workspaces, the total value of the subsidy exceeds $255,500 USD annually in avoided ingestion costs. Pretty good, right?
Comparative Pricing Models
Compared with third-party services (we won’t mention specific software manufacturers), which typically charge based on Monthly Active Rows (MAR), Lakeflow Connect's DBU-based model is more predictable. MAR-based pricing can lead to "bill shock" during massive updates or full refreshes. Lakeflow Connect's cost is tied to the efficiency of the serverless compute rather than arbitrary row counts.

04. Governance, Security, and Unity Catalog Integration
Lakeflow Connect leverages Unity Catalog to provide a centralized governance framework.
The Role of Connection Objects
A "Connection" in Unity Catalog is a securable object that encapsulates credentials and endpoint information for a source system. An administrator can grant USE CONNECTION privileges to a team, allowing them to manage ingestion pipelines without ever seeing the raw API keys or secrets.
End-to-End Lineage and Observability
One significant challenge in data engineering is the "black box" nature of third-party ingestion, where lineage often breaks. Lakeflow Connect captures end-to-end lineage automatically. Unity Catalog tracks the journey of data from the source through the "Bronze," "Silver," and "Gold" layers, which is indispensable for GDPR compliance and data stewardship.
05. The Convergence of Data Ingestion and AI Intelligence
Reliable ingestion is "foundational" to modern analytics and AI agents like Databricks Genie.
Powering Databricks Genie and Genie Code
Databricks Genie lets users engage with data via natural language. Lakeflow Connect's high-frequency updates ensure Genie has access to the current state of the business rather than stale data. Furthermore, Genie Code, an AI agent specifically for data teams, can automate the creation and maintenance of these pipelines. A data engineer can prompt Genie Code to "create an ingestion pipeline for Salesforce Opportunity," and the agent will generate the necessary Spark Declarative Pipeline code.
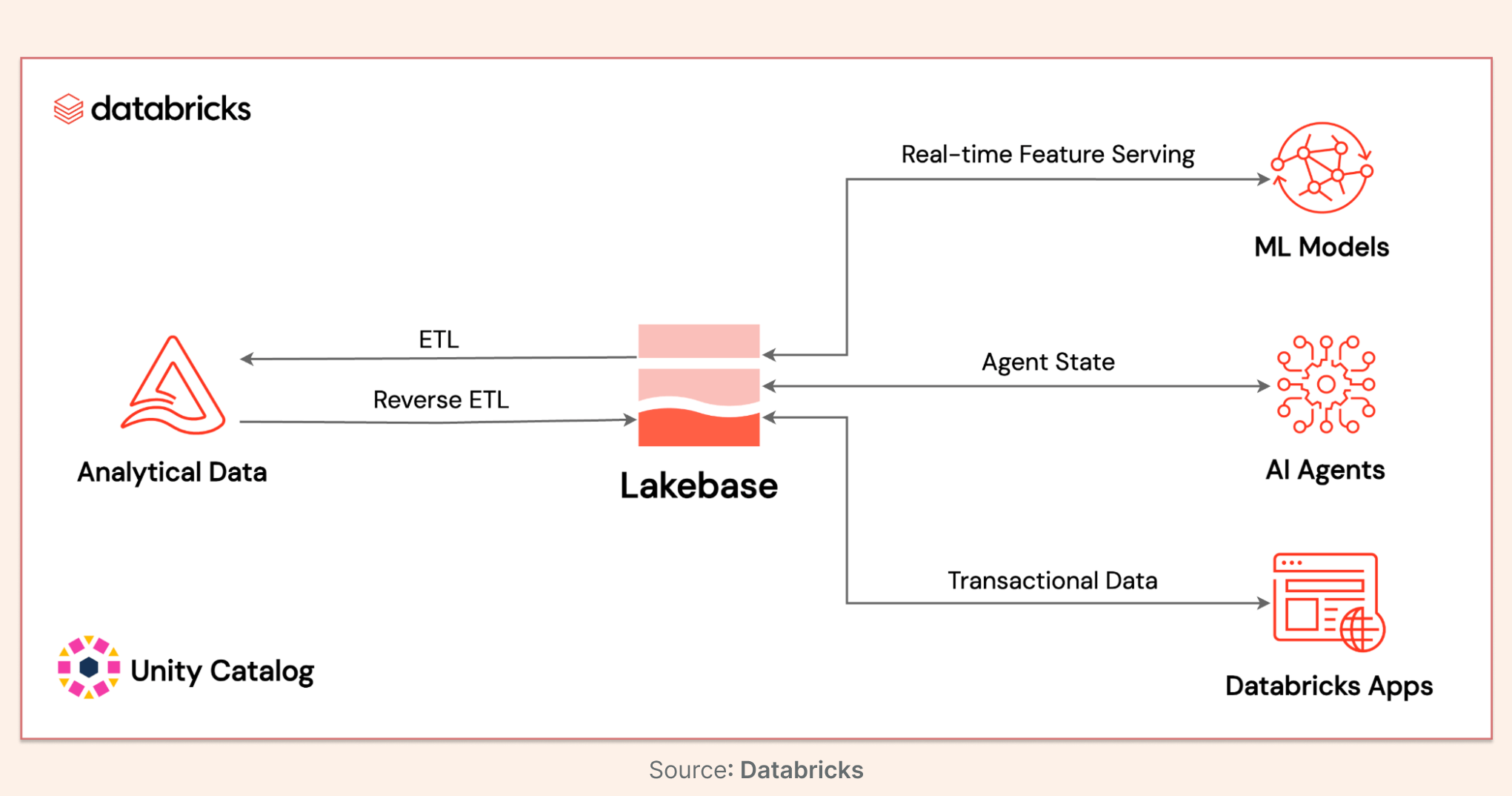
The Role of Lakebase
Azure Databricks Lakebase, now generally available, acts as the operational database for the agentic era. It provides a managed, serverless Postgres service that allows AI agents to manage state and application workflows directly in the lakehouse. Combined with Lakeflow Connect, this creates an ecosystem where data flows in (Lakeflow), and agents can read, write, and reason over it (Lakebase/Genie).
06. Implementation Strategy and Operational Best Practices
Preparation: Ensure Unity Catalog and serverless compute are enabled at the account level.
Connection Setup: Use the "Add Data" wizard to guide SaaS authorization or database gateway deployment.
Pipeline Authoring: For production, use Declarative Automation Bundles to allow for version control and CI/CD integration.
Monitoring: Actively track consumption using the system.billing.usage table, filtering for the LAKEFLOW_CONNECT product origin.
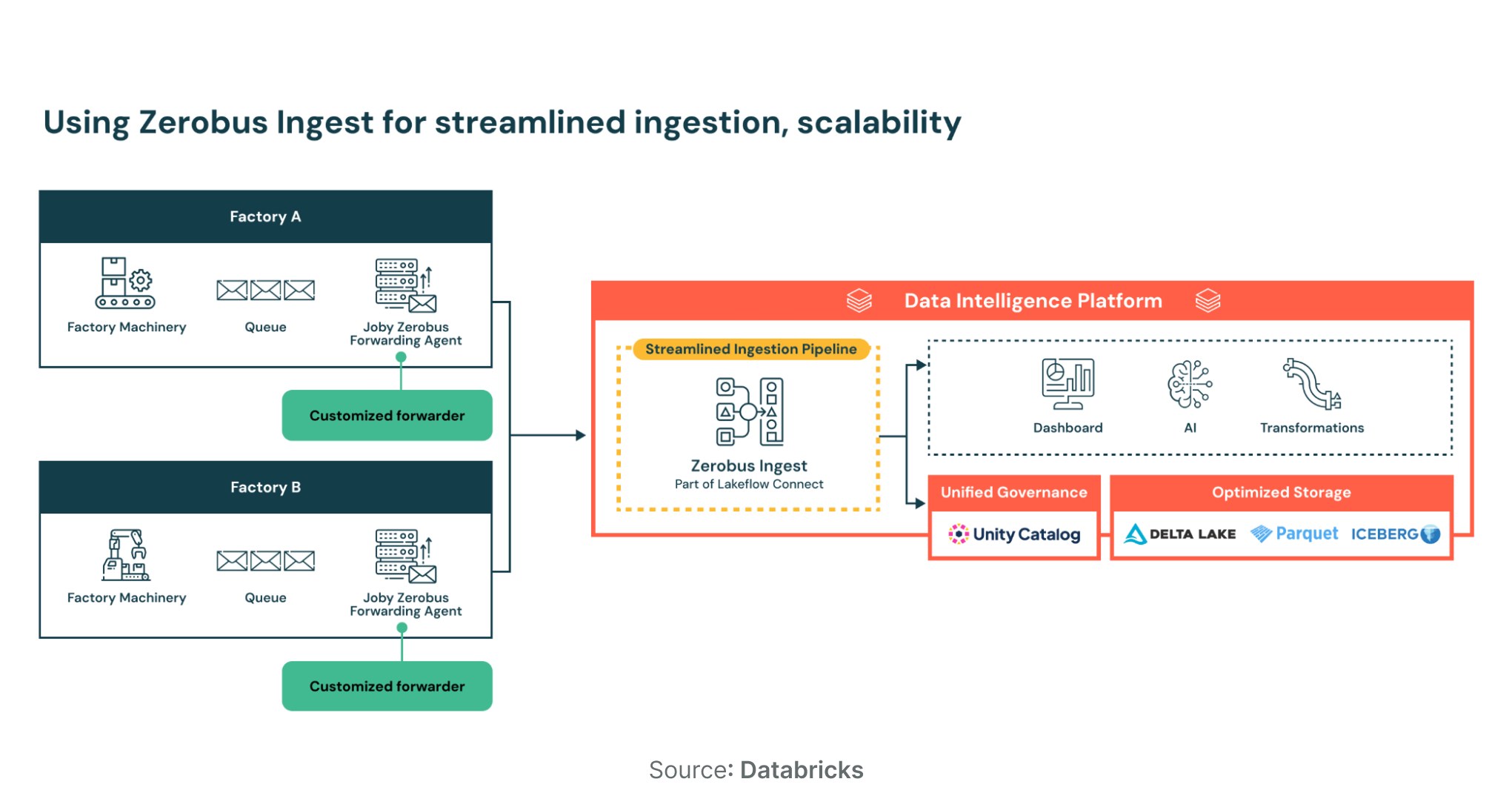
07. Advanced Use Cases: Zerobus Ingest
For real-time event streams, Lakeflow Connect offers "Zerobus Ingest," a serverless direct-write API priced at $0.050 per GB. A 50% promotional discount is active until September 1, 2026, reducing the rate to 0.0715 DBU per GB. This is ideal for webhooks, IoT telemetry, and clickstreams, eliminating the need for intermediate message buses such as Kafka.
Conclusion
The Lakeflow Connect Free Tier on Azure Databricks represents a fundamental shift in the economics and architecture of data engineering. By offering 100 free DBUs per workspace per day, Azure Databricks has democratized high-volume data ingestion, allowing organizations to ingest up to 100 million records per day at no additional compute cost. Organizations embracing this native approach can reduce ETL costs by up to 83% while building the foundation required for agentic AI.
If your team is still paying per row for data that was already yours, it's worth running the numbers. Start by auditing your current ETL spend against what 100 free DBUs per day would cover (for most teams, the gap is smaller than expected).
Sunnydata works with data teams on Azure Databricks to scope, build, and govern production ingestion pipelines using Lakeflow Connect. If you want a clear-eyed view of what migration would actually take, get in touch.