You Pay for the Complexity of Your Move From On-Prem to Cloud
The cloud promises flexibility and scale. But what often gets lost in the hype is the hidden toll of complexity. A typical on-premise-to-cloud data pipeline looks like this:
Run an on-prem tool (runner)
Copy files via FTP from on-prem to cloud in unoptimized format (often csv)
Store it somewhere in the cloud
Orchestrate ingestion into an analytics platform
Load to Analytics platform by using the Medallion architecture, finally to the bronze layer
All this just to move data from point A to point B.

The Complexity Tax
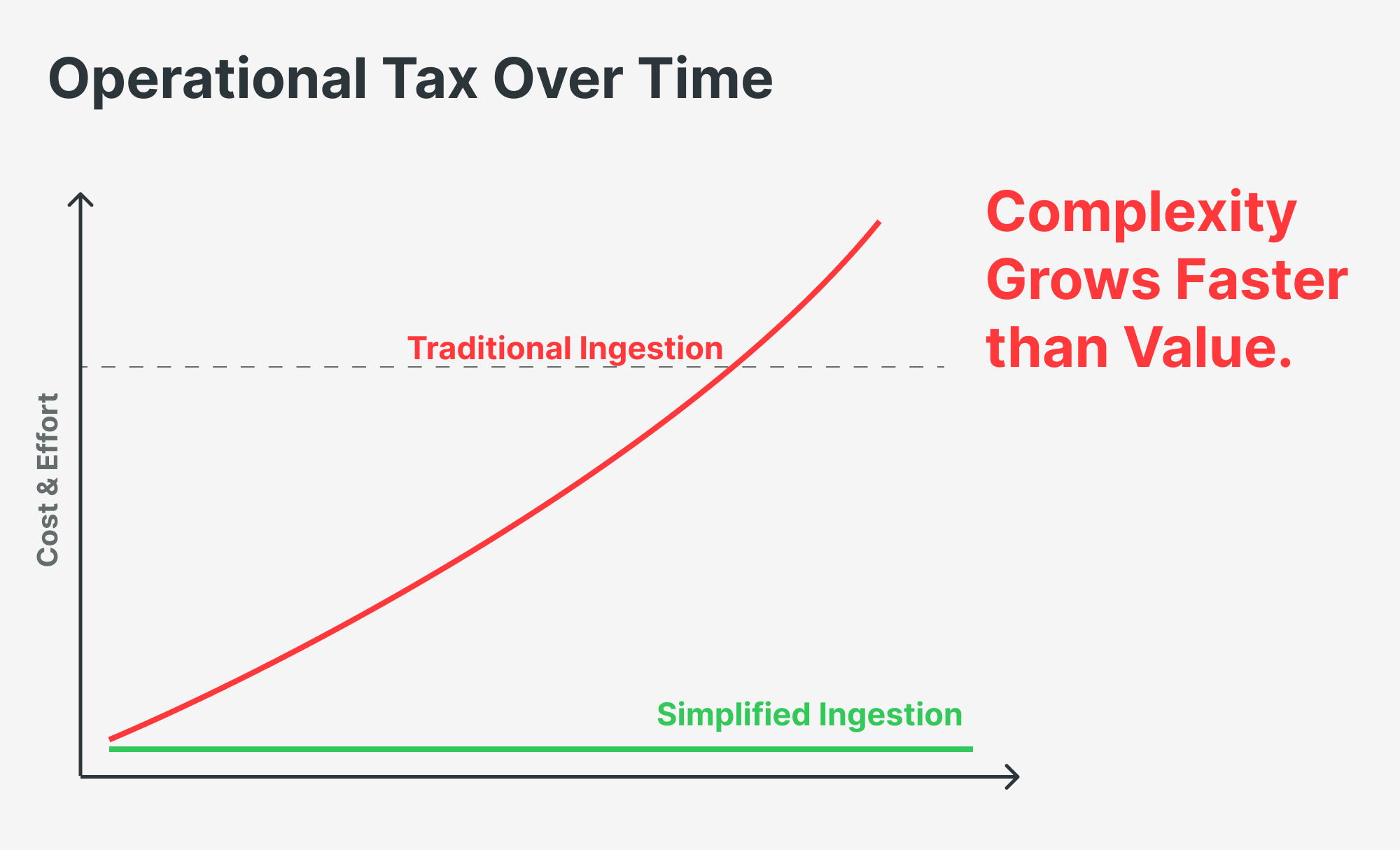
This patchwork creates an operational tax. Every new data source means weeks of work, more scripts, more connectors, and more things that can break. It becomes a jigsaw puzzle that needs constant babysitting.
This complexity doesn’t just slow teams down - it costs real money. In fact, the data infrastructure industry quietly profits from all this complexity - each extra step is another product or service they can sell you. Complexity, it turns out, is often a feature for vendors, not a bug.
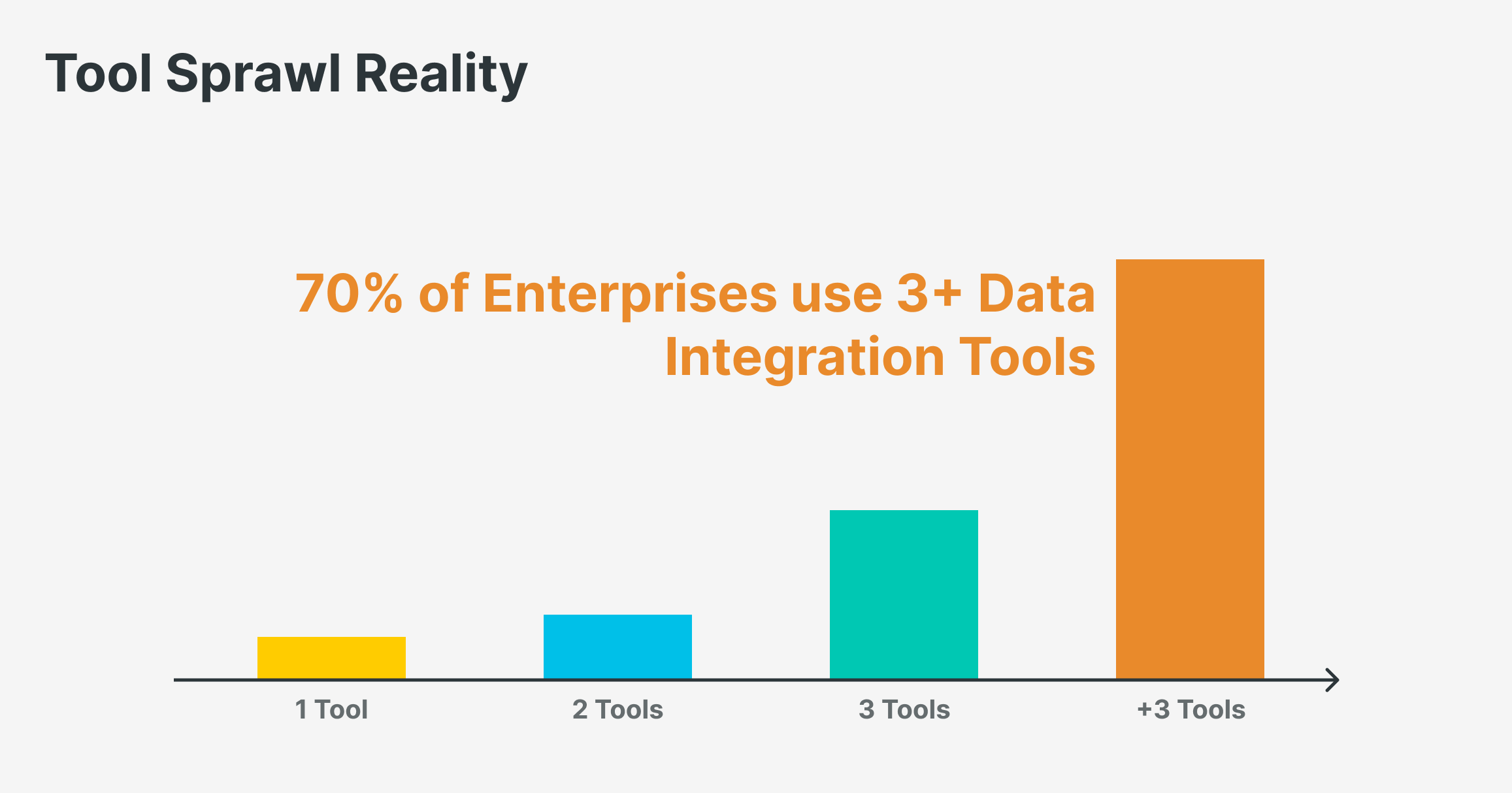
Many companies run multiple ingestion and orchestration tools in parallel. According to Gartner, 70% of enterprises use more than one data integration tool, and half use three or more. The result: higher costs, slower delivery, and less flexibility. You end up paying just to move data, before you get any value from it.
The Hybrid Reality Makes It Worse
Most enterprises will stay partially on-prem or hybrid for years — especially as cloud bills rise due to AI workloads. An IDC survey reported that 86% of CIOs plan to move some workloads back on-prem to control costs, a trend highlighted by Harvard Business School research on cloud repatriation.
In this context, every unnecessary step in a data pipeline is a cost-cutting opportunity.
Because simpler architecture means fewer licenses, fewer systems, fewer renewal conversations.
What If You Just... Didn't?
This is where the conversation gets interesting. What if you didn't need the message bus? Or the FTP server? Or the separate ingestion layer?
This is where Databricks Zerobus Ingest comes in. Zerobus Ingest is a direct ingestion API. There is no message bus in the middle. Instead of routing data through queues, storage layers, and extra systems, applications push events directly into Delta tables using a simple REST or gRPC API (with more protocols coming).
What disappears?
No middlemen
No FTP servers
No extra ingestion infrastructure
As Victoria Bukta, product manager, puts it:
“No more intermediate message buses. No more complex configurations. Just point your application at an endpoint and start sending data.”
ZeroBus was built as a native part of the Databricks Lakehouse, so data lands immediately in governed tables with Unity Catalog — security, lineage, and access control included by default.
Franco Patano, Databricks Solutions Architect, called Zerobus:
“The least hyped feature with the biggest upside.”
He highlights that you can write directly to Delta at up to 100 MB/s with hundreds of streams, with fewer hops, lower costs, and cleaner architecture.
In other words: less to run, less to fix, less to renew.
Business Impact: Simpler Architecture, Lower Costs
Zerobus scales by increasing the number of streams or connections to the service, rather than by managing partitions, brokers, or worker fleets. There’s no need to rebalance topics, tune consumers, or resize infrastructure - scaling is handled by simply opening more connections.
Zerobus Ingest was built as a native part of the Databricks Lakehouse, so data lands immediately in governed tables with Unity Catalog — security, lineage, and access control included by default.
The Simplicity Advantage
From a CEO or CFO perspective, the value is very clear:
Fewer systems
Fewer licenses
Fewer operational costs
Faster access to data
By streaming data straight into the Lakehouse, companies can retire entire layers of technology that exist only to move data around. This reduces what many teams quietly pay today — the “pipeline tax”.
But there's a second-order effect that matters more: simpler systems mean faster iteration.
When your data team spends less time maintaining pipeline infrastructure, they spend more time building things that actually differentiate your business. The competitive advantage isn't in how sophisticated your data plumbing is—it's in how fast you can act on data.
Companies that figure this out will move faster than their competitors. Not because they have better tools, but because they have less tools.
Why This Matters Now
The data infrastructure industry has spent years selling you on the idea that more components = more capability. Specialized tools for every step. Best-of-breed integrations. "Composable" stacks.
But composability has a cost. Every seam is a failure point. Every integration is a maintenance burden. Every vendor relationship is a negotiation.
The hybrid/multi-cloud reality is forcing a reckoning. As cloud bills rise and CFOs demand ROI, the "pipeline tax" (all the money spent just to move data around) becomes impossible to ignore.
Zerobus represents a different philosophy: simplicity as a feature, not a limitation.