Why Financial Institutions Are Ditching Vendor Solutions for Databricks
The Shift: Why Data Teams Prefer In-House Development
When we mention accelerators, we usually refer to technical tools that help us speed up specific projects, such as platform adoption, migration, or automatic code conversion (for example, Lakebridge). However, there’s another category of business-oriented accelerators, whose narrative has traditionally been dominated by vendors offering seemingly ready-to-use products, but at the cost of expensive licensing and limited flexibility due to their standardized nature.
Organizations are systematically dismantling their packaged data solutions. These off-the-shelf solutions (some very high-quality, others not so much) will become frequent targets for decommissioning within organizations over the coming years. Indeed, this is already happening, and we have an increasing number of projects that prove it. Institutions will increasingly seek greater control and cost optimization over their internal solutions to ensure their entire internal investment in Data & AI generates real returns.
The era of vendor dependency is ending. Data teams have spent years building the foundation (data lakes, reports, essential infrastructure) while delegating the development of data-driven applications to product-based vendors. This made sense when internal capabilities were limited and time-to-market pressures were intense. But that's over.
Source: SunnyData
Your data team is now more capable than the vendors you're paying. The democratization of knowledge and AI-powered development tools has transformed internal capabilities, while teams have gained years of hard-won experience. They've reached a maturity level that makes expensive vendor solutions obsolete. Add cost reduction pressures, and you have the perfect justification for decommissioning those licensed products, especially the mediocre ones that never delivered on their promises...
In 2025, we’re all aware that Data & AI involves much more than simply data handling, and that real value generation also depends on foundational software engineering principles. This becomes obvious with the release of services like Databricks Apps, to simplify application development, or Databricks Agent Bricks, to tackle complex ML/AI scenarios. These releases prove that data teams need to evolve into something bigger thanreport generators.
The Best Databricks Accelerators for Financial Institutions
In this blog, we’ll focus on public and free artifacts or accelerators that can serve as a foundation for developing internal data-driven applications addressing 7 challenges often faced by financial institutions.
1. Compliance. Anti-Money Laundering (AML) & Know Your Customer (KYC)
This solution accelerator provides a blueprint for building data-driven AML transaction monitoring and KYC analytics on the Databricks Lakehouse.
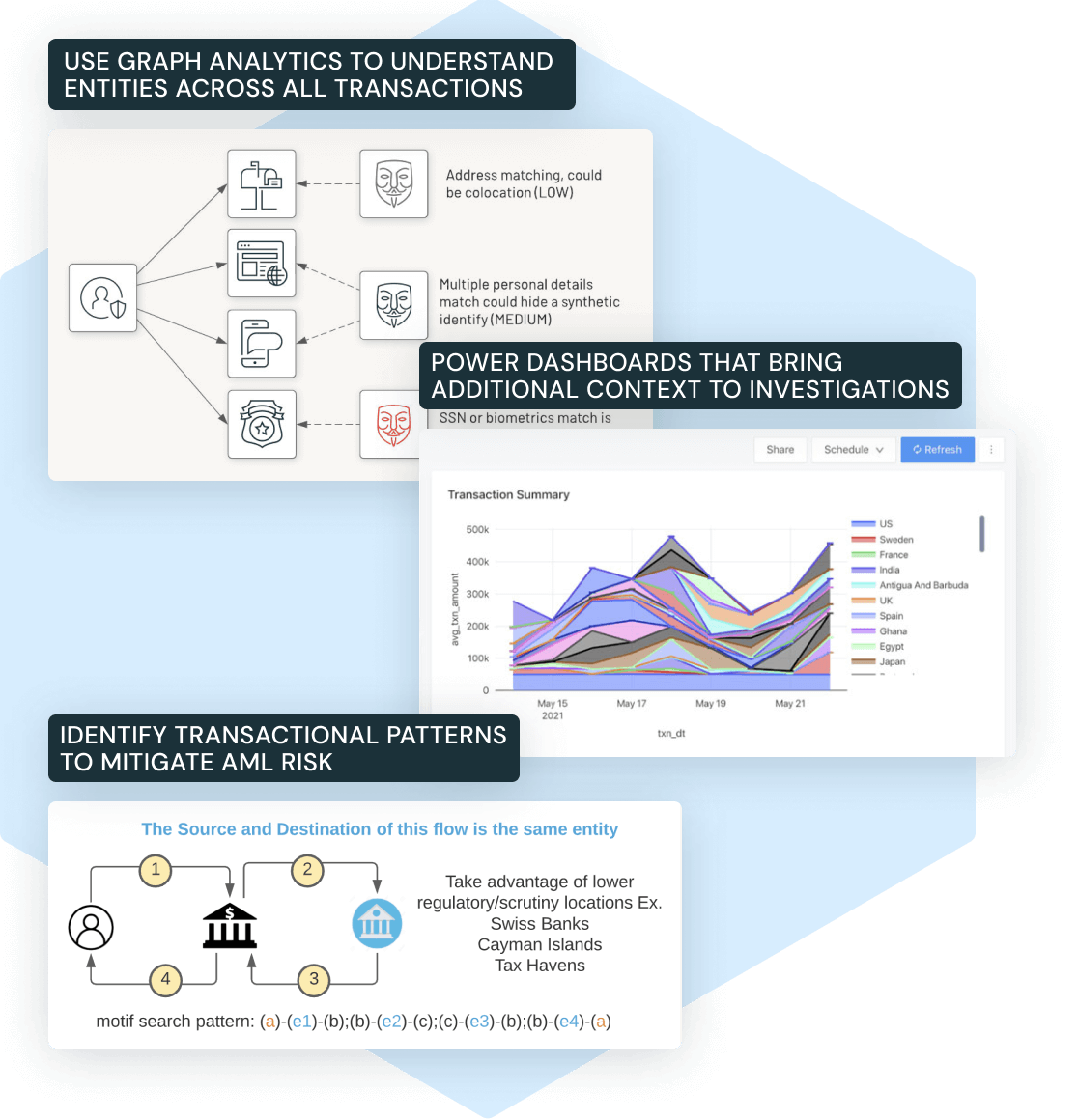
Source: Databricks
It enables analysis of billions of transactions for anomalies (to catch fraud/money laundering) and delivers high-quality, transparent data lineage for regulators. By leveraging big data and machine learning, financial institutions can reduce false positives and improve investigative efficiency in AML operations.
This open approach can replace or complement traditional licensed AML systems (e.g., NICE Actimize or SAS AML platforms) by offering similar detection capabilities on a scalable, cloud-based architecture.
In short, banks can adhere to evolving AML regulations and counter financial crimes with an in-house solution, instead of relying solely on vendor-provided compliance software.
Challenge #2 Fraud Detection & Financial Crime Prevention
Real-Time Fraud Detection Accelerator
Databricks offers accelerators to build real-time fraud prevention engines that combine rule-based patterns with machine learning models. This helps institutions preempt fraud by flagging suspicious transactions using business rules and augmenting them with ML anomaly detection, thereby responding to bad actors rapidly.
2. Fraud Detection & Financial Crime Prevention
1. Real-Time Fraud Detection Accelerator
Databricks offers accelerators to build real-time fraud prevention engines that combine rule-based patterns with machine learning models. This helps institutions preempt fraud by flagging suspicious transactions using business rules and augmenting them with ML anomaly detection, thereby responding to bad actors rapidly.
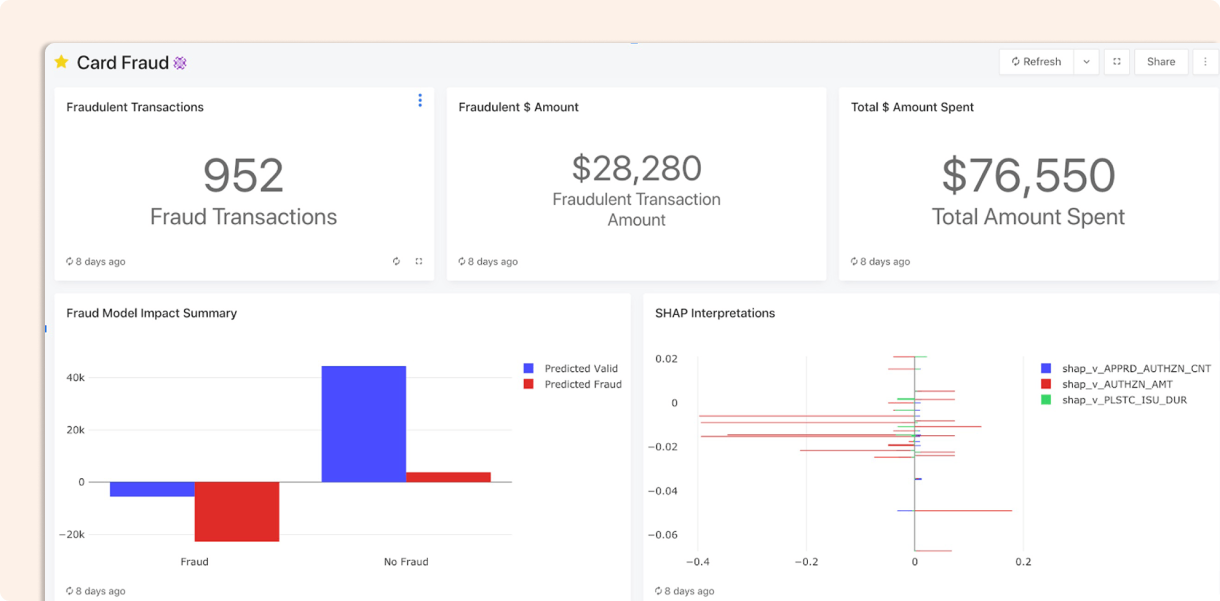
Source: Databricks
The accelerator features an orchestration framework (using MLflow, decision trees, etc.) to detect fraud in streaming transaction data and minimize operational losses.
2. Geospatial Fraud Analytics Accelerator

Source: Databricks
Another accelerator focuses on analyzing credit card transactions with geospatial data to identify abnormal usage patterns. It demonstrates how to detect anomalies, such as impossible travel (cards present in two distant locations within a short time), by combining location intelligence and real-time analytics.
Geospatial analysis helps distinguish normal spending from abnormal spending behavior, building customer trust by enhancing fraud detection accuracy.
Using these accelerators, financial firms can modernize their fraud prevention workflows, potentially decommissioning expensive end-to-end fraud management tools.
By migrating fraud rules and models onto the open Databricks Lakehouse, banks could reduce reliance on AI-driven fraud platforms such as Feedazi or on legacy systems like FICO’s Falcon. The result is a flexible, scalable fraud prevention capability fully under the institution’s control.
3. Customer Personalization & Insights (Transaction Analytics)

Source: Databricks
This accelerator helps banks unlock rich customer insights from card swipes and payment transactions. It includes notebooks for merchant classification and transaction enrichment, which automatically categorize raw transaction records with merchant names, categories, and brands.
By contextualizing billions of transaction data points, banks get a 360° view of customer spending behavior and preferences. On top of that, the solution applies behavioral clustering and graph analytics to segment customers and identify patterns (an approach inspired by natural language processing techniques applied to purchase sequences).
These techniques enable hyper-personalized marketing (for example, grouping customers by similar purchase habits to tailor offers). The accelerator even examines regularity of payments to infer things like recurring bills or income indicators, which can feed credit risk or KYC processes.
By adopting this accelerator, financial institutions can replace or augment licensed customer analytics and personalization platforms with a custom in-house solution. Rather than relying on third-party marketing analytics tools, banks can directly analyze their own customer transaction data to drive personalization.
Banks could decommission components of a costly customer data platform by using Databricks to build similar segmentation and recommendation models tailored to their needs. This saves on software licensing and provides deeper, proprietary insights into customer behavior that packaged solutions might not offer.
Accelerator's Page - Transaction Enrichment With Merchant Classification
Blog: Hyper-Personalization Accelerator for Banks and Fintechs Using Credit Card Transactions
4. Risk Management & Model Governance
Co-developed with EY, this solution accelerator streamlines the governance of machine learning and statistical models across the financial enterprise. It automatically generates model documentation and audit reports for every new model, capturing details needed for compliance and internal review.

Source: Databricks
The accelerator includes templates and dashboards to track model metadata, performance, and validation results, among others, bringing transparency throughout the model lifecycle.
This helps the model validation team identify model risks and ensures adherence to regulations around model governance. It removes guesswork and manual effort from compliance by providing a complete audit trail for models in production.
Implementing this accelerator can replace manual processes or expensive licensed software for model governance. For example, some banks use vendor solutions like SAS Model Risk Management to maintain a centralized model inventory and documentation repository.
By using Databricks, organizations can build a similar centralized model registry and automated documentation process on an open platform. This reduces licensing overhead and allows more flexible integration with the bank’s data and ML pipelines. In effect, an in-house Lakehouse-based model risk system can decommission legacy model governance tools, while satisfying regulators with greater transparency and control
5. Insurance Claims Automation
Designed for insurance companies, this accelerator demonstrates an end-to-end claims processing pipeline built on the Lakehouse. It automates key steps of the claims workflow (ingesting claims, policy, and even IoT/telematics data) and uses AI to extract actionable insights for adjusters.

Source: Databricks
With machine learning, the solution can flag potential fraud in claims, triage claims by severity, and even provide explainable recommendations for claim outcomes.
By augmenting claim data with predictive analytics, insurers can expedite human investigations, reduce bias (through consistent AI guidance), and maintain an audit trail for every claim decision. The net effect is faster settlements, lower claim handling costs, and better fraud detection during the claims process.
This accelerator enables insurers to modernize claims management without depending entirely on licensed core systems. Many insurers today use core claims management software. By integrating Databricks’ Smart Claims accelerator, an insurer could replace add-on modules from those core systems (or legacy rule-based claims engines) with bespoke ML-driven capabilities.
For instance, instead of purchasing a separate fraud detection module for Guidewire, an insurer could leverage the Databricks solution to detect fraud and advise adjusters in real time, thereby decommissioning certain vendor add-ons.
Over time, as the Lakehouse handles more of the analytics, insurers can transition away from heavily customized, licensed claims platforms to a more open and agile solution, while still using the core system for record-keeping and workflow.
Challenge #6 AI-Powered Customer Service (LLM Analytics)
This is a newer accelerator that helps institutions (particularly insurers and banks) apply large language models to customer support and call center operations. It provides pre-built code to analyze unstructured text data from sources like call transcripts, chat logs, and support emails. By fine-tuning LLMs on this data, the solution can detect customer intent and sentiment, categorize inquiries, summarize conversation threads, and even assist in automating responses.

Source: Databricks
For example, an insurance call center can use the accelerator to automatically classify the topic of each customer call (billing question, claim status, new policy inquiry, etc.) and route it to the correct team, or use an LLM to suggest answers to an agent in real time.
The notebooks also show how to unify internal knowledge base data with external data to improve an AI chatbot’s performance, and how this reduces underwriting risk by spotting issues in free-form text (like an applicant mentioning something that impacts risk).
By deploying this accelerator, financial institutions can build their own intelligent customer service AI instead of buying one. Many banks have turned to licensed customer service analytics and chatbot solutions (for instance, solutions built on IBM Watson Assistant or other NLP platforms) to improve support.
With Databricks, however, they can train custom models on their proprietary data, achieving similar outcomes without vendor lock-in. This means a bank could replace a third-party customer support AI tool by developing an in-house LLM that is tailored to its products and clients.
The result is improved call center efficiency and customer experience, using cutting-edge AI that the institution fully controls and continuously improves – all without paying per-seat or per-ticket fees to an outside provider.
Challenge #7 ESG Investing & Sustainability Analytics
Environmental, social, and governance (ESG) factors are increasingly important in finance. Databricks delivers accelerators that provide firms with a data-driven view of ESG metrics and sustainable investing. One notebook helps analyze a company’s ESG performance by aggregating data (e.g., emissions, board diversity, controversies) and using NLP techniques to derive insights from textual reports. Another part of the solution shows how to operationalize ESG by embedding these metrics into internal dashboards and decision-making processes.
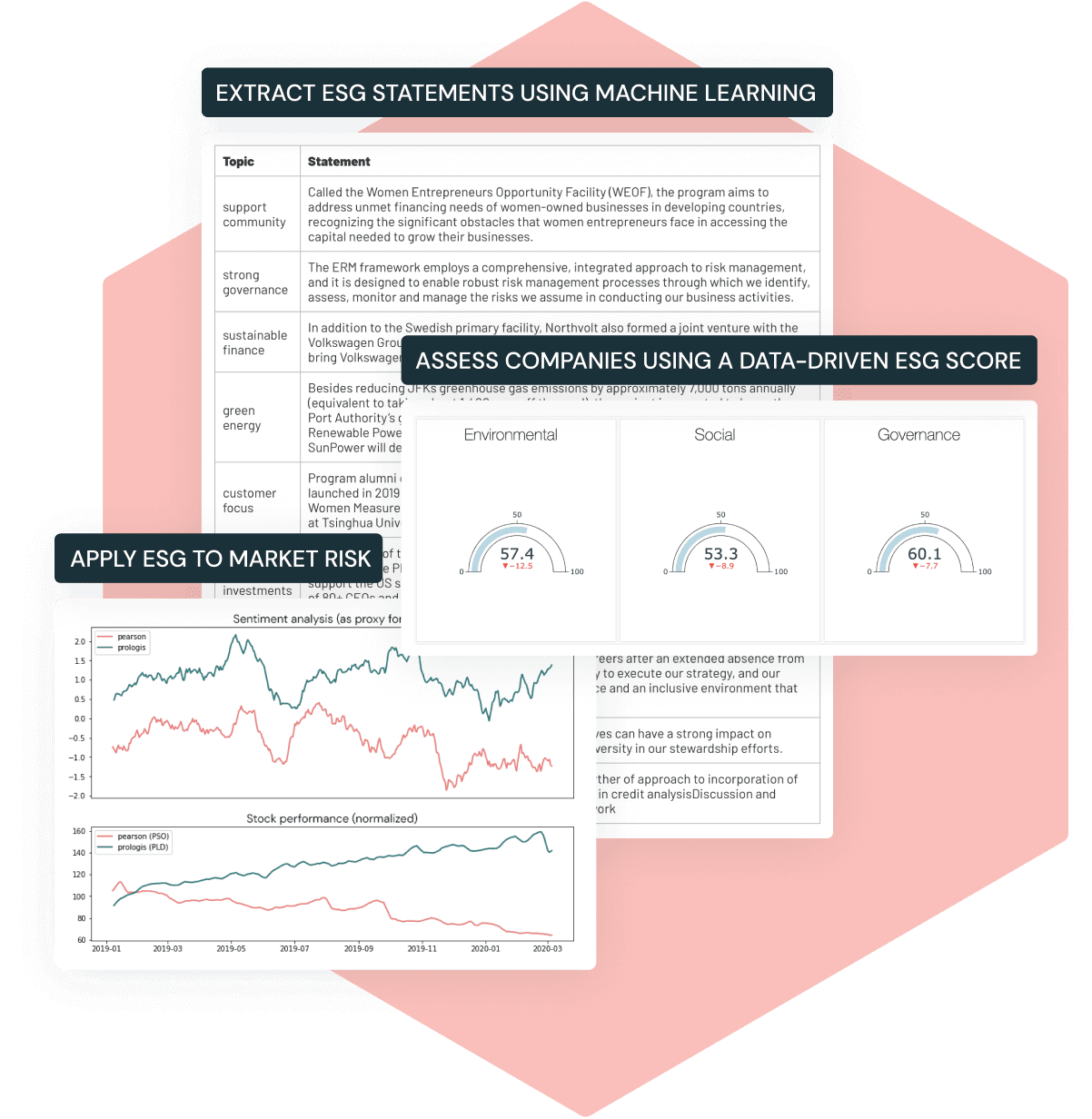
Source: Databricks
With this accelerator, a financial institution can quantify the sustainability and societal impact of its investments or loans, and even model scenarios (like carbon footprint reduction over time) using AI. For example, it combines graph analytics and NLP on ESG news to assess companies’ reputational risk.
Adopting the ESG accelerator enables banks and asset managers to perform ESG analysis in-house, reducing reliance on licensed ESG data vendors and ratings providers. Traditionally, firms have purchased ESG risk ratings from agencies such as MSCI or Sustainalytics, which orient their sustainable investments. While those ratings are useful, building an internal ESG analytics capability means the firm adapts the scoring models to its criteria and has full transparency into how scores are derived.
In practice, a bank could use Databricks to integrate various ESG datasets and develop proprietary risk scoring models, possibly phasing out some subscriptions to external ESG rating services. The accelerator jump-starts this process by providing a template to ingest ESG data and create dashboards, enabling a cost-effective, custom ESG solution for compliance reporting or product development (e.g., green bonds, ESG-focused portfolios).
Conclusion: A New Era of Self-Reliant Data Teams
Both technological advancements and evolving business needs are driving a significant shift in the use of data accelerators: organizations are moving away from relying on proprietary “black box” solutions toward building internal data products leveraging open platforms like Databricks.
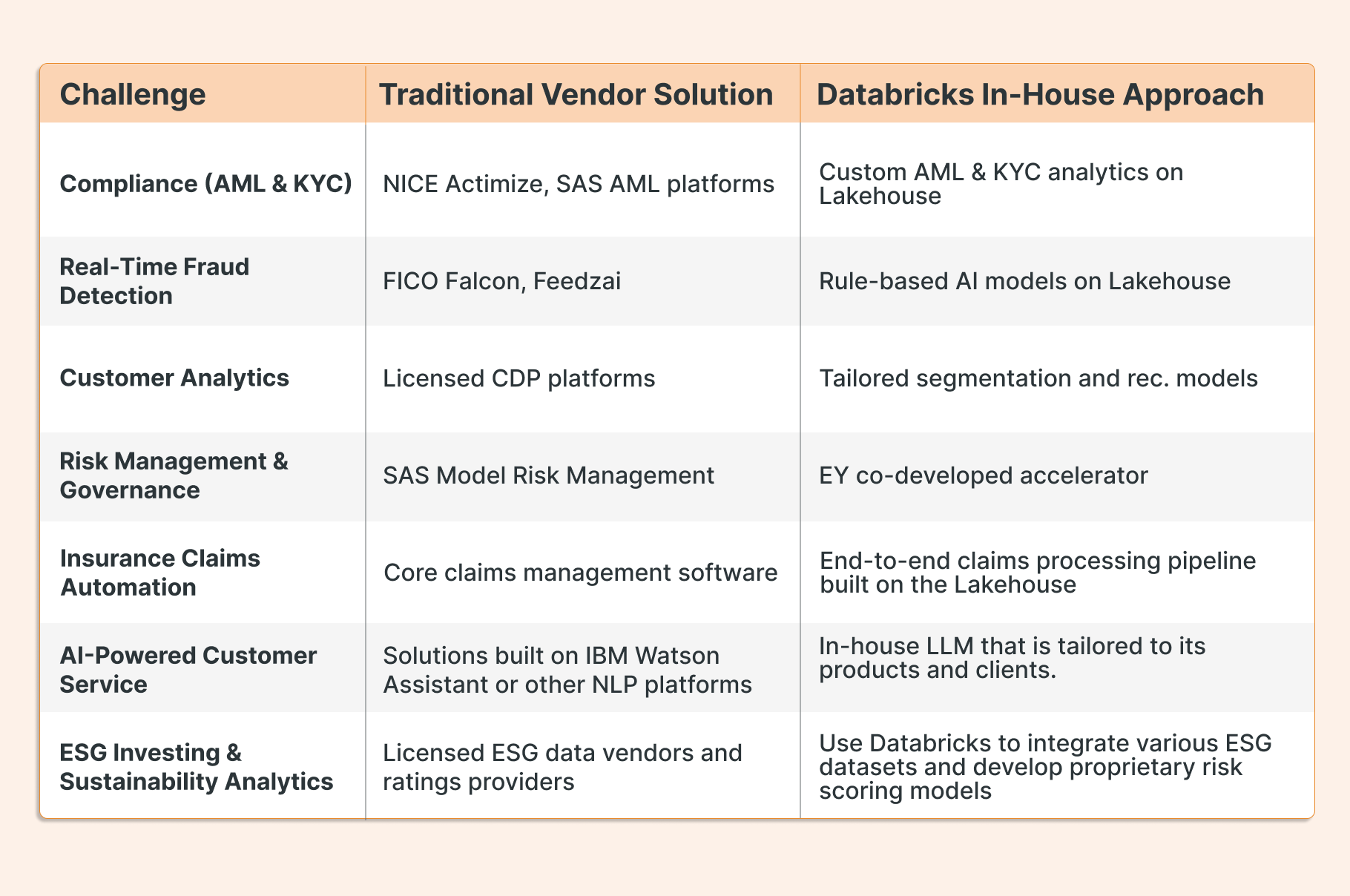
The examples we explored (from AML compliance and fraud detection to customer personalization, model governance, insurance claims automation, AI-powered customer service, and ESG analytics) reveal that in-house data teams can now deliver industrial-grade solutions.
This shift is not only emerging but gaining momentum rapidly, empowering internal data teams to develop products previously relying on costly third-party tools. In essence, solution accelerators provide ready-to-use foundations, so institutions can build their data product factories, achieve greater control, reduce costs, and foster a more innovative and self-sufficient data culture for the future.