CI/CD Best Practices: Passing tests isn't enough
This blog focuses on core CI/CD practices for software development in general, including test automation, deployments, and validations. However, towards the end, it also explores the unique challenges faced in data projects, where data quality becomes just as critical as code quality.
Can a CI/CD Pipeline Fail Even if All Jobs Pass?
CI/CD is often described as the process that automates the deployment. It includes actions like testing, building, and deploying, but sometimes those steps are not enough. A pipeline can be completed successfully while still deploying something that's not working as intended.

This usually occurs when the pipeline checks whether the technical steps ran, but not whether the final outcome makes sense from a functional or business point of view. And this isn’t exclusive to one type of software: it can happen with an API returning inaccurate responses, a web app failing to show data, or a microservice saving inconsistent records.
That’s why it’s good practice to ask: “If all jobs run successfully, is the result actually reliable?” If you can’t confidently say yes, the pipeline needs better validations.
Where Should Validations Happen?
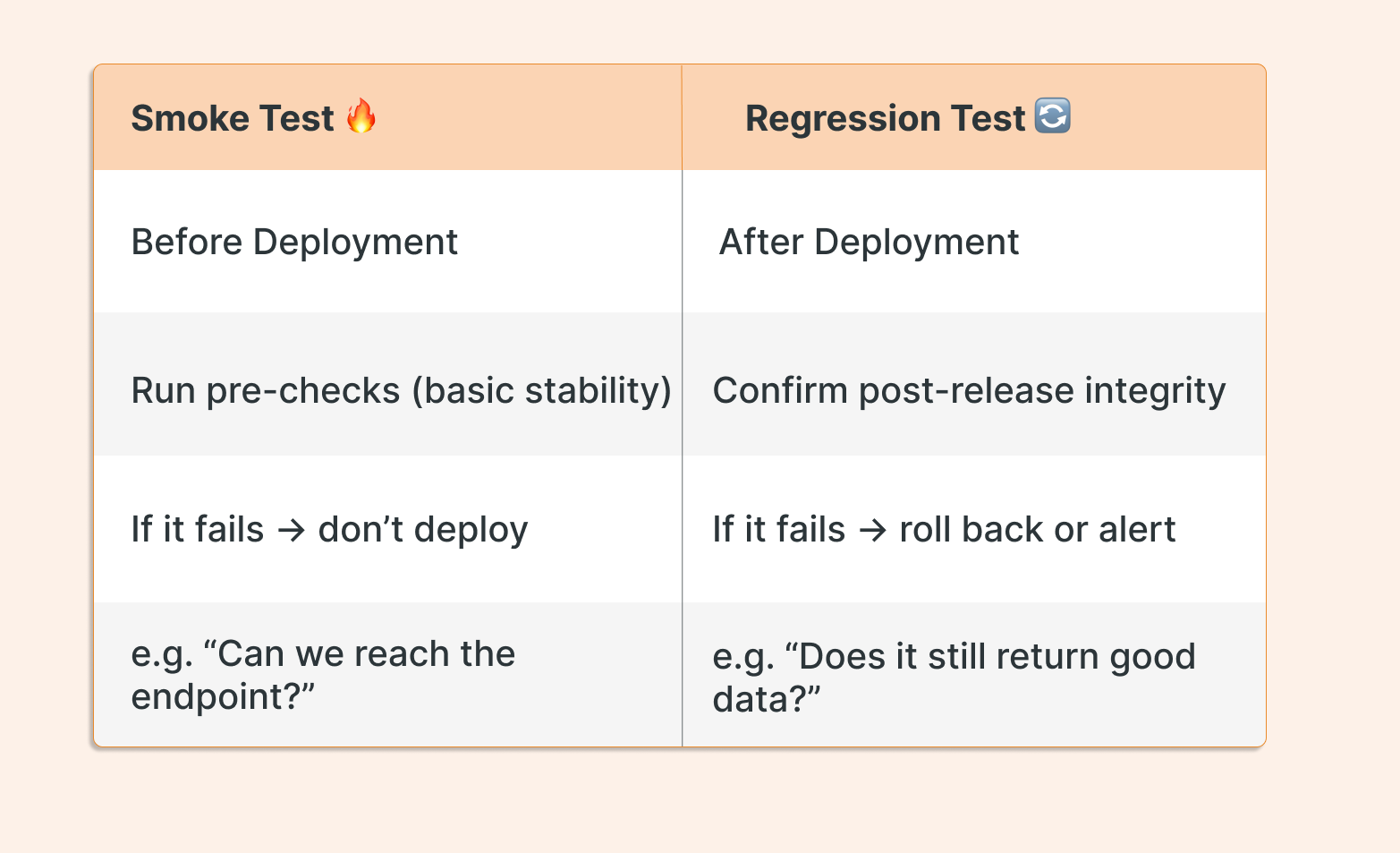
Validations in a CI/CD pipeline can happen at two key moments:
Before Deployment (CI): to ensure the release won’t break anything critical and that the software is always in a working state.
After Deployment (CD): to confirm that the system behaves as expected in a real environment.
Validating at both points helps you catch issues early and react fast when something breaks. They’re different checks, but they complement each other.
This is what smoke testing (in the CI stage) and regression testing (in the CD stage) are for. Simple but essential practices when you want a reliable pipeline.
Smoke Testing (Before Deployment)
Smoke testing refers to lightweight validations that are executed before deployment to ensure that the basic functionality of the software is intact. It's like a pre-check to decide whether it's stable enough to continue with the release and further testing processes. If the basics don’t work, there’s no point moving forward
These checks help catch obvious issues before they reach production. They don’t take much effort, but they can save you from a lot of headaches.
In practice, a smoke test might:
Check basic functionalities.
Run small scripts to verify DB connectivity.
That the system returns a valid response.
They’re quick checks designed to answer one question: “Is this good enough to continue with the rest of the pipeline?”
You can embed these as simple YAML steps or call external (e.g., Python) scripts for reusable logic. Here's a common example:
- name: Run smoke test script
run: |
echo "Running smoke tests..."
echo "Checking main endpoint..."
python scripts/smoke_check_api.py
These validations run before deployment starts, and if they fail, the pipeline stops. The point is to confirm that the system is alive and responsive. In the above example, the pipeline calls a Python script that performs the checks.
If a validation is complex or needs to be reused, it’s a good practice to keep it as a separate script. This also helps keep the YAML clean.
Here’s how the external Python script (smoke_check_api.py) might look:
import requests
import sys
URL = "https://api.com"
try:
response = requests.get(URL, timeout=5)
if response.status_code == 200:
print("The endpoint responded correctly.")
else:
print(f"Endpoint returned {response.status_code}, expected 200")
sys.exit(1)
except requests.exceptions.RequestException as error:
print(f"Could not connect to the endpoint. Details: {error}")
sys.exit(1)
Regression Testing (After Deployment)
Regression testing refers to checks performed after deployment to ensure that recent changes haven't broken existing functionalities. These validations act as a safety net to catch unexpected side effects.
This type of validation happens at the end of the pipeline. Once the deployment finishes, a step is added on the CD YAML file to check that existing functionalities look right in the target environment (usually production). These checks confirm that the system is working as expected and that the new changes didn’t break anything essential. You’re not re-running the entire test suite, just validating the most critical pieces.
Regression tests might:
Check main API endpoints still respond correctly
Confirm a web page loads without errors
Test a key function returns expected results
These aren’t full functional tests, they’re minimal checks to ensure that what used to work still works.
In practice, a regression test in the CD stage can be exactly the same as a smoke test in the CI stage. The difference isn't in the script itself, but in when and why it's executed. Before deployment, a smoke test helps decide if it's safe to proceed. It's a quick sanity check. After deployment, the same check acts as a regression test to confirm that the core functionality is still working in the real environment. You're asking the same question, “Is this still working?”, but at two different moments in the pipeline, and for two different reasons: to prevent a bad release vs. to validate the impact of a release.
Thus, an example of the YAML during CD stage might call an external script like the example below, and that script can be identical to the one used during the smoke testing phase.
- name: Run regression test after deployment
run: |
echo "Running regression tests..."
echo "Checking main endpoint..."
python scripts/regression_test_api.py
CI/CD in Data Projects

CI/CD pipelines in data projects face a set of challenges that don't usually appear in traditional software development. In most software projects, a passing pipeline typically means the system is safe to deploy. But in data projects, that's not always true. These pipelines often deploy code that generates reports, runs analytical models, or modifies tables through SQL or scripts. When that happens, code correctness isn’t enough. Teams need to ensure the outputs are meaningful and trustworthy. This is where data correctness enters the picture.
Even if a CI/CD pipeline passes all its jobs, it can still deploy changes that produce incomplete, duplicated, or invalid data. That’s why CI/CD for data projects must go beyond unit tests or build checks. It needs domain-specific validations that confirm the integrity, completeness, and trustworthiness of the output, especially when working with transformations or business logic. These checks don’t replace data pipeline monitoring, but they help prevent broken logic from reaching production in the first place. Without these, pipelines can give a false sense of success, silently introducing errors that impact downstream.
For example, you can add a validation step that compares the current number of records in a table against historical averages, to detect unexpected drops caused by faulty filters or joins. Here is a YAML example adapted for Databricks and the notebook referenced:
- name: Run validation notebook on Databricks
env:
DATABRICKS_HOST: ${{ secrets.DATABRICKS_HOST }}
DATABRICKS_TOKEN: ${{ secrets.DATABRICKS_TOKEN }}
run: |
databricks jobs run-now --job-id 12345
This assumes a Databricks Job has already been created via UI or CLI.
# Databricks notebook: Validate row count drop in final_table
from pyspark.sql import SparkSession
# Load current data
final_table = spark.table("schema.final_table")
current_count = final_table.count()
# Load historical average (stored in a stats table)
stats_table = spark.table("schema.table_stats")
historical_avg = stats_table.filter("table_name = 'final_table'").selectExpr("AVG(row_count)").first()[0]
threshold = 0.8 # Minimum acceptable count (80% of historical average)
min_acceptable = historical_avg * threshold
print(f"Current row count: {current_count}")
print(f"Historical average: {historical_avg}")
print(f"Minimum acceptable: {min_acceptable}")
if current_count < min_acceptable:
raise Exception("Validation failed: Row count dropped significantly below historical baseline.")
else:
print("Row count is within expected range.")
This kind of check can catch silent failures where business-critical rows disappear due to a subtle change in logic. In short, when CI/CD is part of a data project, it's not just about code, it’s about confidence in the results.
Make Sure to Include Alerts

It’s not enough to detect errors you also need to notify the team when something goes wrong. That’s why automated alerts are essential.
If a validation fails, the pipeline should send a message to a channel like Slack or Teams. For Slack, this is done using an Incoming Webhook. You generate a URL from Slack, store it as a GitHub Secret, and send a message from the pipeline only when something fails.
Here's a simple example:
- name: Send Slack alert on failure
if: failure()
run: |
curl -X POST -H 'Content-type: application/json' \
--data '{"text":"Validation failed in CD pipeline. Please review the logs."}' \
${{ secrets.SLACK_WEBHOOK_URL }}
Beyond automating alerting at the right time is essential. That’s when CI/CD stops being just a workflow and becomes a real support tool for the team.
Final Thoughts
As software development continues to evolve through new architectures, faster delivery cycles, or the growing presence of data-driven applications, pipelines need to keep up.
That means going beyond checking if jobs pass and validating what really matters: the result. Sometimes this means ensuring an API still works, other times it’s confirming that a dataset wasn’t silently corrupted. Including checks for things like data correctness doesn’t mean replacing proper data pipeline monitoring, it just means adapting them to reflect what software looks like today.
Adding proper validations and alerts means you can:
Catch issues early
Prevent pipelines from showing success when problems exist
Get immediate team notifications when issues arise
The goal is always the same: build pipelines you can trust. Because at the end of the day, success isn’t just a green checkmark. It’s knowing that what you delivered works.
I'd like to express my sincere gratitude to Sofía Meroni for her feedback and insights throughout the writing process of this article. Her expertise in DevOps and thoughtful suggestions significantly improved the quality of this content.