Your Databricks Stack Is Modern. Your Orchestration Isn't.
Most teams that move to Databricks get the hard part right. They migrate the processing engine, rebuild the transformation logic, and stand up Unity Catalog. Then they leave Azure Data Factory running in the background: connected to everything, owned by nobody, and quietly accumulating cost and complexity.
That's the gap this post is about.
The Platform Stopped Moving. That's the Problem.
ADF isn't failing. It's just not keeping up.
The last meaningful update to the core product dates to August 2024. And Microsoft's direction is clear: ADF's future is inside Microsoft Fabric, under a different pricing model, on a different platform. If your data stack is built on Databricks, that's not a migration path — it's a divergence. In an era where your processing engine, governance layer, and AI tooling are evolving every quarter, an orchestration layer pointing the wrong direction isn't a neutral choice but a compounding liability.
ADF's release notes. The last entry: August 2024.
This isn't about ADF being "too expensive" in the abstract. It's about what it costs to maintain a tool that isn't moving in the same direction as the rest of your stack.
Slow platform innovation becomes a business risk. When your orchestration layer can't keep pace with your data platform, delivery slows down, debugging gets harder, and your governance story develops gaps. We'll cover the Unity Catalog lineage problem in detail in a future blog. For now, the short version: when ADF moves or triggers data outside the Databricks environment, Unity Catalog can't see it. That data just appears. The lineage chain breaks, and what should be a 360° view of your data becomes a manual auditing exercise.
What This Actually Costs
The billing model is where ADF gets quietly expensive at scale.
Every pipeline lookup, loop iteration, and external trigger is a billable Activity Run. In simple architectures, it's manageable. In production environments with complex pipelines, high-frequency ingestion, and thousands of partitions, orchestration costs can reach 30% of the total data bill. Not because anyone planned for it, but because the meter never stops running.
Lakeflow Jobs doesn't charge for orchestration. You pay for the compute you were already going to use. The orchestrator itself costs nothing. That difference compounds quickly in high-volume environments.
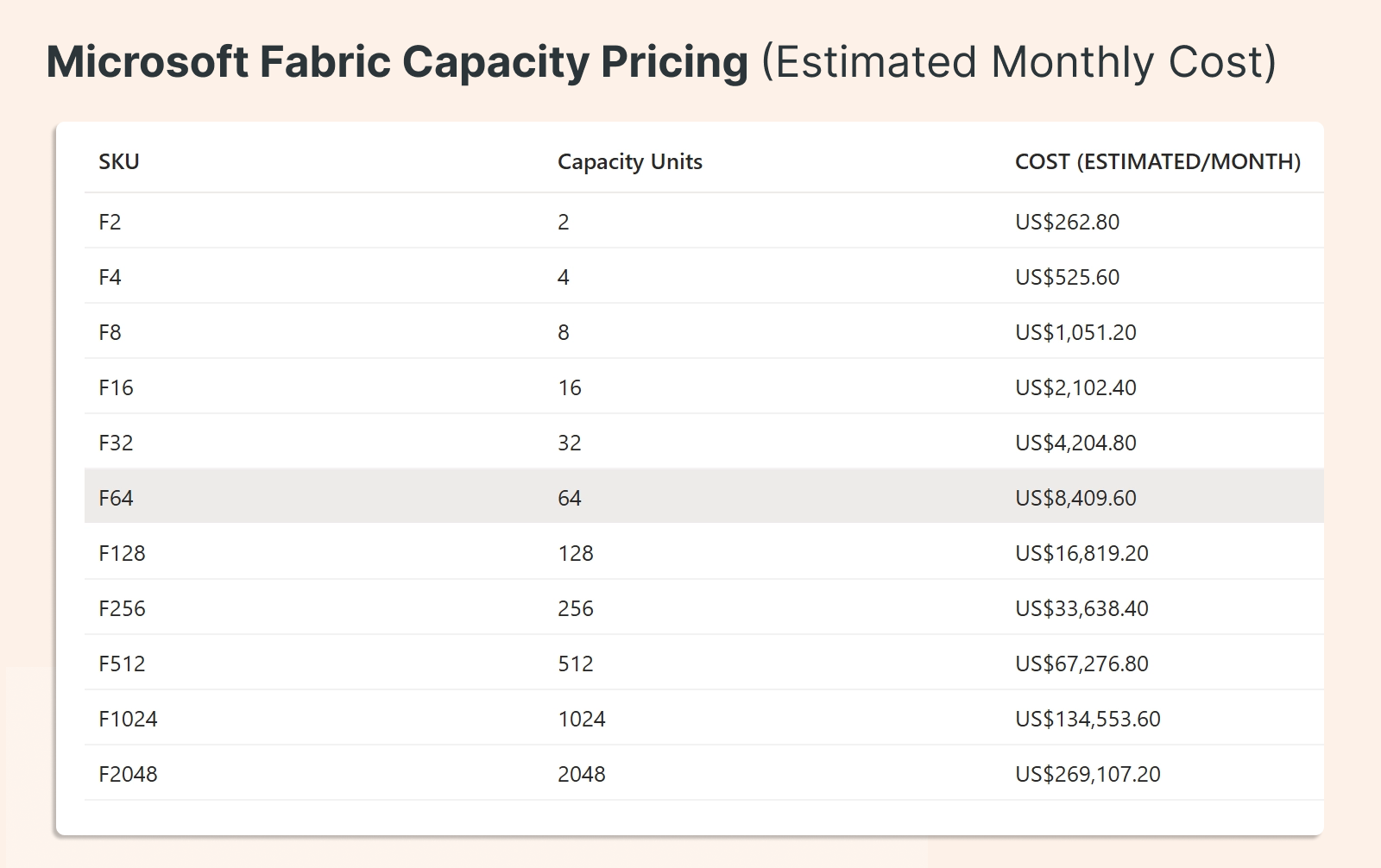
Fabric ADF changes the model, but not in the direction you might expect. Rather than pay-per-run, you're moving to capacity-based pricing: paying for reserved hours, including idle time. It's a legitimate option if you're already deep in the Microsoft Fabric ecosystem, but it's a fundamentally different cost model, and it keeps orchestration outside Databricks. If Databricks is already your main platform, that trade-off is hard to justify.
What Replaces ADF
This is the practical question, and it has direct answers.
Task and job orchestration → Lakeflow Jobs. Native DAGs, built-in triggers, retry policies, backfills, and monitoring. All inside the Databricks control plane. No API handshake between an external orchestrator and your clusters. No cold start latency from an outside trigger. The transition between tasks happens within the same system.
File and blob ingestion → Native landing patterns. Structured, governed, and consistent.
Incremental file ingestion → Auto Loader. It's mature, it handles schema inference and evolution cleanly, and it's one of the strongest parts of the migration story. If your current ADF architecture is mostly file-based, Auto Loader alone eliminates a significant portion of what ADF is doing.
Connectors → Review case by case. Keep only what you actually need. Most standard RDBMS connections (SQL Server, Postgres, Oracle, MySQL) move cleanly via direct JDBC or Lakeflow Connect. Lakeflow Connect also covers Salesforce, ServiceNow, Kafka, Event Hubs, and most cloud storage sources natively.
The one area where ADF stays useful temporarily: niche connectivity like SAP ECC or S/4HANA, where licensing constraints and application complexity make direct JDBC a non-starter. If that's your blocker, keep ADF as a controlled bridge for that specific source, not as the orchestration layer for everything else.
The On-Prem Blocker (And How to Remove It)
The most common reason teams stay on ADF longer than they should isn't cost or connectors. It's the on-prem runner.
In many environments, cloud pull isn't permitted. Security policy requires data to be pushed from on-prem systems to the cloud, not pulled by a cloud service reaching into the network. ADF's Self-hosted Integration Runtime solved this, but it created a dependency that made the whole orchestration layer feel immovable.
It isn't. The push-based pattern solves this cleanly. Zerobus Ingest is a direct ingestion API built natively into the Databricks Lakehouse. Applications push events directly into governed Delta tables via REST or gRPC, with Unity Catalog security and lineage included by default. No message bus in the middle. No extra storage layer. Data lands in governed tables immediately.
Remove the on-prem blocker, and the last reason to keep ADF disappears with it.
Where Does Your Team Sit?
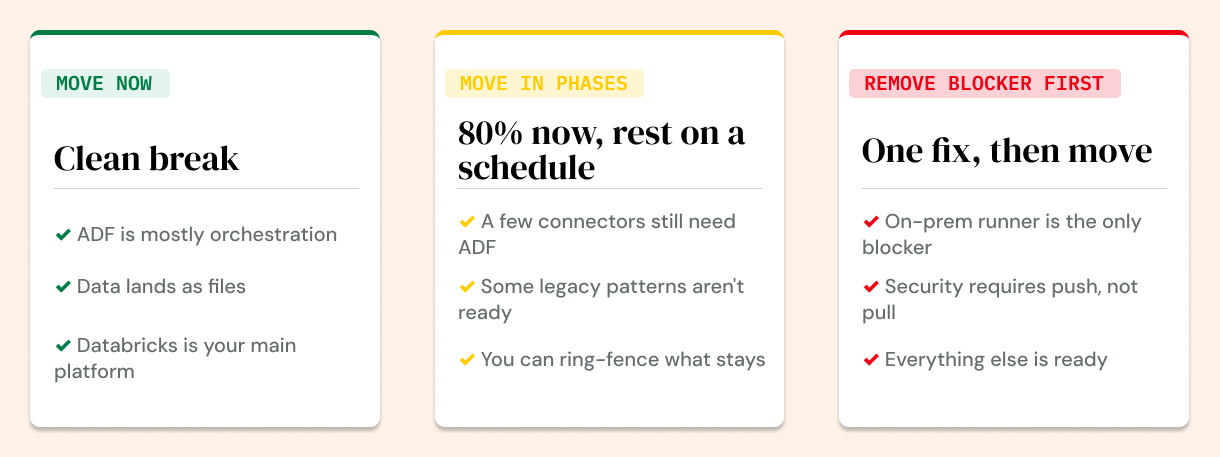
Three migration paths, depending on where you are:
Move now. ADF is mostly orchestration. Most of your data lands as files. Databricks is already your primary platform. The pieces are in place. The migration is a simplification, not a rebuild.
Move in phases. A few special connectors or legacy patterns still depend on ADF. Migrate the 80% that's clean, put a retirement schedule on the rest. Don't let the edge cases hold the core hostage.
Remove the blocker first, then move. Your only real dependency is the on-prem runner. Swap it for a push-based ingestion pattern, then decommission ADF. This is a sequencing question, not a technical barrier.
The Real Default Has Changed
ADF made sense as the default when Databricks needed an external orchestrator to tie everything together. That's no longer the case.
Lakeflow Jobs is the better default when Databricks is already your main platform. Fewer tools to manage. No split logic across systems. Better alignment with where AI, engineering, and governance are heading. And an orchestration layer that moves as fast as the rest of your stack.
In the AI era, the higher cost isn't the ADF bill. It's staying on a platform that isn't evolving.
In a future blog, we’ll go deeper into the Mirror Syndrome that keeps ADF alive through migrations, why Unity Catalog lineage breaks when ADF is in the picture, and how to think about the architecture decisions that make the difference between a migration and a modernization. Stay tuned.