Why Your Databricks Upgrade Is Incomplete If You're Still Running ADF
Part 1 made the case for moving. This post explains why most teams don't, and what it's actually costing them.
The Mirror Syndrome
In 90% of the migrations we see, the same thing happens.
The technical team pours everything into upgrading the processing engine. Azure Synapse to Databricks is the most common case right now — and it's the right call. But while the new platform gets all the attention, Azure Data Factory gets quietly reconnected to the new environment and left running exactly as before.
We call this the Mirror Syndrome. The stack looks modern. The orchestration is a copy-paste of the old one.
It's not laziness. It's a pattern with three distinct causes — and one of them is on the consulting side.
Why It Keeps Happening
Inertia paralysis. ADF's visual interface is comfortable. Teams know it. It works. The classic "if it ain't broke, don't fix it" — except in data engineering, today's convenience compounds into tomorrow's bottleneck. Keeping ADF because it feels familiar is choosing planned obsolescence on a schedule you don't control.
The false economy of redirection. Lots of teams convince themselves that pointing existing ADF pipelines at new Databricks notebooks is faster than migrating the orchestration. It isn't. You're paying an engineer hours to patch an architecture you'll want to scrap in two or three years when the Activity Runs bill arrives. You pay for the patch today. You pay for the redesign tomorrow. It's a double expense with no upside.
The Consultant-Waiter problem. Some consulting firms — either because they lack deep Databricks expertise or because they don't want to complicate a sale — act as order-takers. They migrate what you ask them to migrate and leave the rest alone. If your consultant isn't pushing you to decommission ADF while you modernize the processing layer, they're not advising you. They're just following instructions. And for that, you don't need an expert.
The Governance Gap Nobody Talks About
This is the argument that should end the debate for any team with a serious data governance mandate.
Unity Catalog is powerful because it captures lineage automatically — for everything running inside the Databricks environment. Workflows jobs, SQL queries, notebooks: UC records the relationship between data and logic without you lifting a finger. From raw ingestion to the dashboard query your CFO runs every Monday morning, you get a complete, unbroken chain.
ADF breaks that chain.
Every time ADF moves data or triggers a copy activity, it happens outside the Databricks control plane. Unity Catalog can't see it. To UC, the data just appears — or disappears. What should be end-to-end lineage becomes a black box. Your traceability story falls apart exactly where it matters most: between the source system and the Lakehouse.
The architecture question isn't just "what does orchestration cost?" It's "what does a broken governance story cost when a regulator asks where that number came from?"
Keep ADF in the picture, and you can't answer that question cleanly.
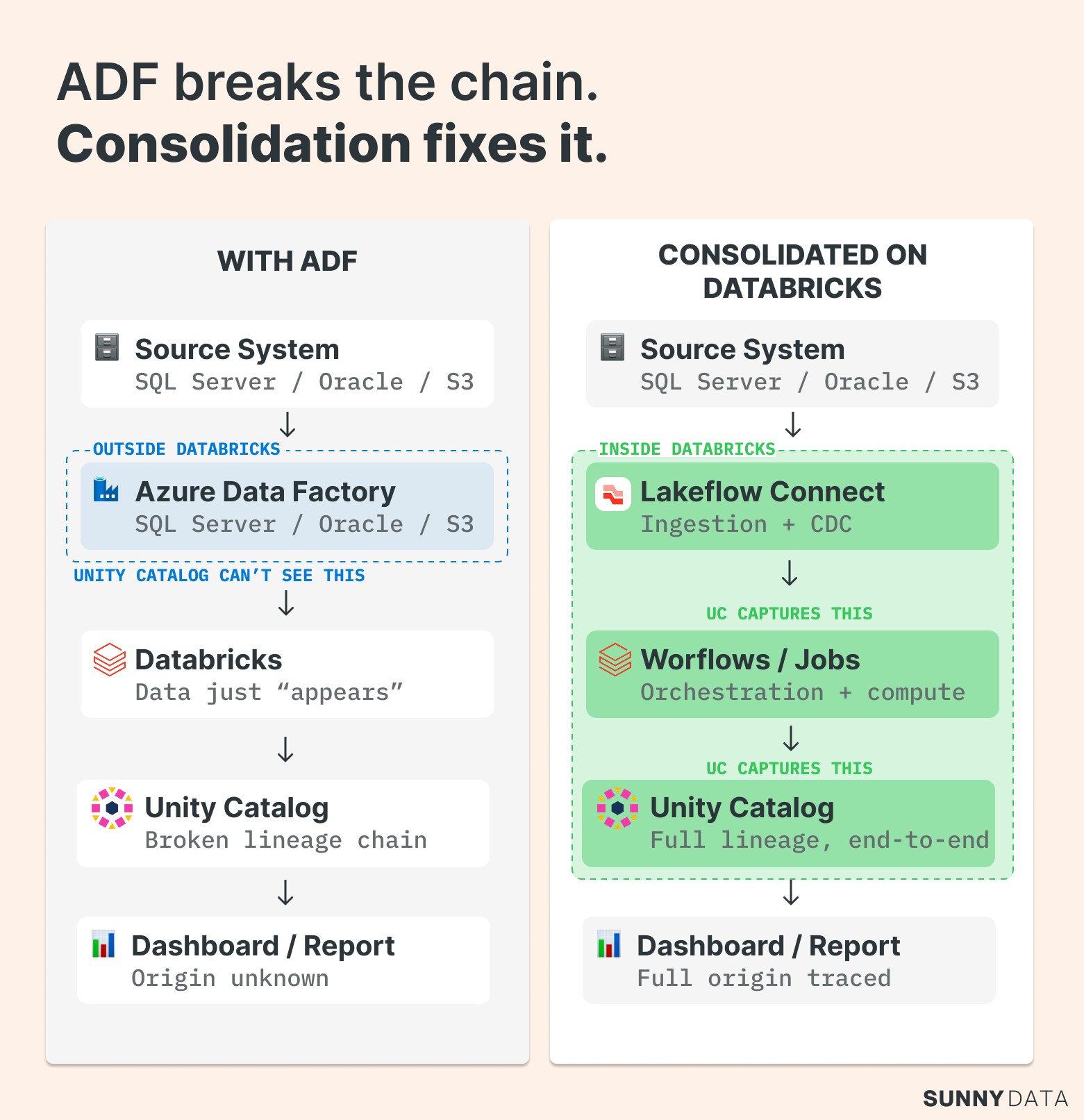
What Replaces It: The Tools That Actually Close the Gap
Lakeflow Connect
Lakeflow Connect is a low-code ingestion platform that connects source systems to Delta Lake declaratively. As of early 2026, native connectors cover the ground that ADF handled for most teams:
Databases: Oracle, SQL Server, MySQL, PostgreSQL, DB2. Cloud sources: Salesforce, ServiceNow, Google Analytics, Workday. Streaming: Kafka, Event Hubs, Kinesis. Files: S3, ADLS, GCS via Auto Loader. Capabilities include CDC, schema inference, schema evolution, and error handling out of the box.
For the 90% of standard RDBMS connections that teams have historically routed through ADF, Lakeflow Connect is the direct replacement. It's not a workaround — it's the cleaner architecture.

Original Source: Databricks
Databricks Workflows / Jobs
This is where the orchestration argument gets concrete.
Workflows isn't a task scheduler. It's a native orchestration engine built into the Databricks control plane — designed to coordinate everything from a simple pipeline to a complex, multi-system data ecosystem.

Jobs are the top-level execution container. Built-in retry policies and configurable timeouts mean you stop waking up at 3am because of a transient network error. Job Clusters spin up for a specific task and tear down when it's done — reducing compute costs by up to 30% compared to always-on clusters.
Tasks are where the engineering happens. Within a Job, Tasks form the DAG — dependencies defined explicitly, execution order enforced automatically. Conditional logic (if-then-else) means orchestration is no longer linear: if data quality validation fails, route to a Slack alert; if it passes, load the production table. Parallel execution lets you run multiple tasks simultaneously to compress your operational window. And it's not just notebooks anymore — you can natively run dbt projects, Python scripts, JAR files, and trigger a Power BI model refresh the moment your data is ready.
Triggers determine how the system reacts to the real world. Schedule-based execution covers the standard cases. File arrival triggers fire the moment a file lands in cloud storage — no polling, no latency. Continuous execution handles use cases that need to be live always.

The performance implication is real. Every time ADF launches a task in Databricks, there's an API handshake: token validation, resource allocation, and cold start management from an external trigger. Workflows eliminates the intermediary. Task A to Task B happens within the same control plane. For near real-time or micro-batch processes, that latency difference is the margin between meeting and missing a business SLA.
When you combine this level of control with Unity Catalog lineage and serverless compute, the question stops being "why should I migrate?" and becomes "why am I still paying for an external tool to do something my platform already does better, for free?"
The Pragmatist's Exception
We're not dogmatists. There are real scenarios where keeping ADF temporarily is the right call — and pretending otherwise is bad advice.
Niche connectivity. Lakeflow Connect is closing the gap fast, but it hasn't closed it completely. SAP ECC and S/4HANA are the clearest examples: connecting directly via JDBC is often a non-starter because of indirect access licensing and application-layer complexity. ADF's native SAP CDC connector handles that diplomacy better than a custom Spark wrapper. Keep it for that specific source. Not for everything else.
Network fortressing. Sometimes the barrier isn't the software — it's the walls around it. Legacy mainframes like IBM iSeries/AS400 often sit behind a Self-hosted Integration Runtime that security teams approved years ago and won't revisit quickly. If establishing new Private Links, firewall rules, and Databricks drivers exceeds the current migration budget or timeline, ADF stays as a temporary bridge. Not as the orchestration layer — as a controlled legacy component with a retirement date attached.
The thousand-pipeline problem. Massive technical debt changes the sequencing question. When you have thousands of legacy processes running, a big-bang migration is operationally dangerous. The right approach: migrate the 20% of pipelines that generate 80% of your orchestration costs or sit on the critical path of your SLAs. Put a retirement schedule on the rest. You're not keeping ADF because it's better — you're running it as a controlled legacy component while the heavy lifting moves to where it belongs.
Where This Leaves You
The Mirror Syndrome is a solvable problem. The tools are mature. The migration paths are well-defined. The governance argument alone should be enough to move the conversation with any data leader who's serious about Unity Catalog.
What we see slow teams down isn't technical complexity — it's the absence of a clear internal mandate to finish the job. If your Databricks migration is live but ADF is still running, the migration isn't finished. It's paused.
The cost of leaving it paused compounds every quarter: in Activity Runs, in lineage gaps, in the engineering hours spent maintaining two orchestration contexts instead of one.
If you're not sure which migration path fits your situation, Part 1 of this series has the decision matrix.