Prioritize AI Quality by Establishing a Data Quality Pillar
As Jacqueline Li, Databricks Product Manager for Data Quality Monitoring, puts it: "Data powers everything in modern enterprises, and as AI use cases grow, so do expectations for data quality. To keep up with today's scale, teams need more than static rules — so they can confidently use their data to drive their business forward."
It's a sentiment that resonates across the industry. Every CEO understands "garbage in, garbage out." The difference today is the scale of impact: outdated or unreliable data can now mislead Q&A bots, pricing agents, or automated decision workflows — at enterprise speed.
Amazon saw this when it automated product-page creation with GenAI. For the first few weeks after launch, roughly 80% of results were unreliable. The lesson isn't that GenAI is broken, but that quality must be engineered and continuously monitored, like any mission-critical system.
AI quality is now a top priority for CEOs
AI is rapidly moving from pilot projects to production, and executives are feeling the impact when issues arise. According to Harvard Business Review’s 2026 AI & Data Leadership Executive Benchmark Survey, 93% of companies now report that interest in AI has led to a greater focus on data. That same survey found the highest-ever percentage of respondents (also 93%) pointing to human issues, culture, and change management as the key challenges to data and AI adoption.
Focusing on data is a positive step. But it is not the same as establishing a data quality pillar.
A lakehouse is necessary but not sufficient for AI readiness
Implementing a lakehouse does not automatically ensure AI readiness. While it provides storage, compute, and governance, true AI readiness means consistently demonstrating that the data supporting critical models and agents is accurate, current, and auditable.
As one HBR analysis notes, a hallucination (a false or inaccurate output presented as true) typically occurs when a model isn't grounded in the input data. If that input data is incomplete, undocumented, or unreliable, AI systems will reflect that uncertainty.
Many organizations now have more data than ever, yet their confidence in using it has declined.
The Data Quality Pillar: six executive-grade requirements
For AI-critical datasets, your organization should be able to demonstrate the following requirements within the platform itself — not just in presentations.
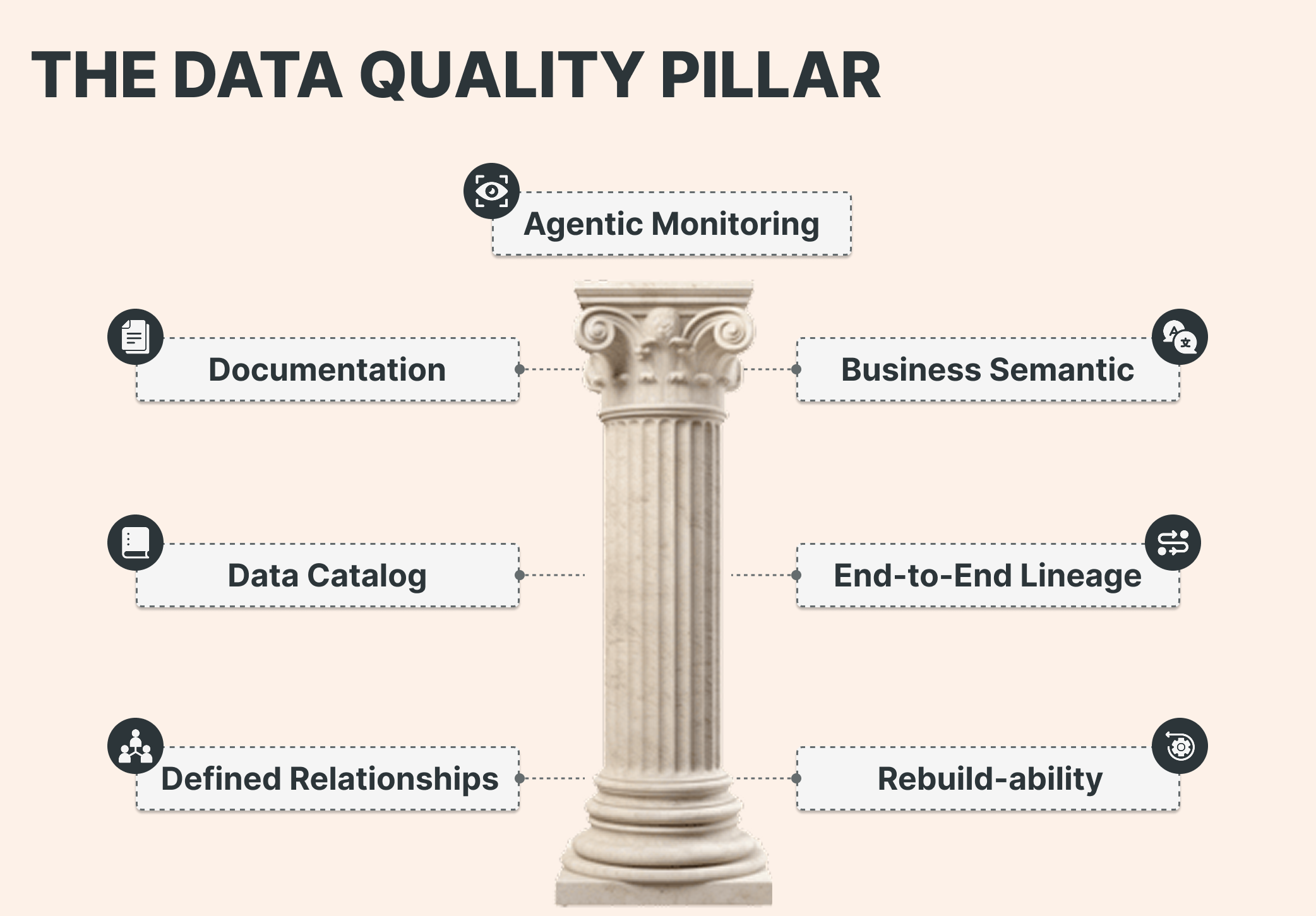
1. Documentation Every table and key field has meaningful descriptions.
2. Business logic (metrics views / business semantics) Governed metric definitions replace duplicated logic scattered across dashboards, notebooks, and scripts.
3. Everything is in the catalog Critical data is discoverable, classified, and assigned a designated owner or steward.
4. Lineage is end-to-end Downstream dashboards, features, and AI outputs are traceable back to upstream jobs, transformations, and source systems — including external lineage in Unity Catalog.
5. Relationships are defined (PK/FK) Defining primary and foreign key relationships ensures predictable joins and reduces silent errors in analytics and machine learning features.
6. Rebuildability is real (versioned DDL + recovery path) Versioned DDL exists for gold tables, and teams can reliably recreate them. Think of DDL the way you think of application code: it belongs in version control.
Once these six pillars are in place, agentic monitoring supports the next stage of scale
Databricks recently announced Data Quality Monitoring at scale with Agentic AI, with a clear framing: manual, rule-based data quality does not scale as data estates grow for analytics and AI.
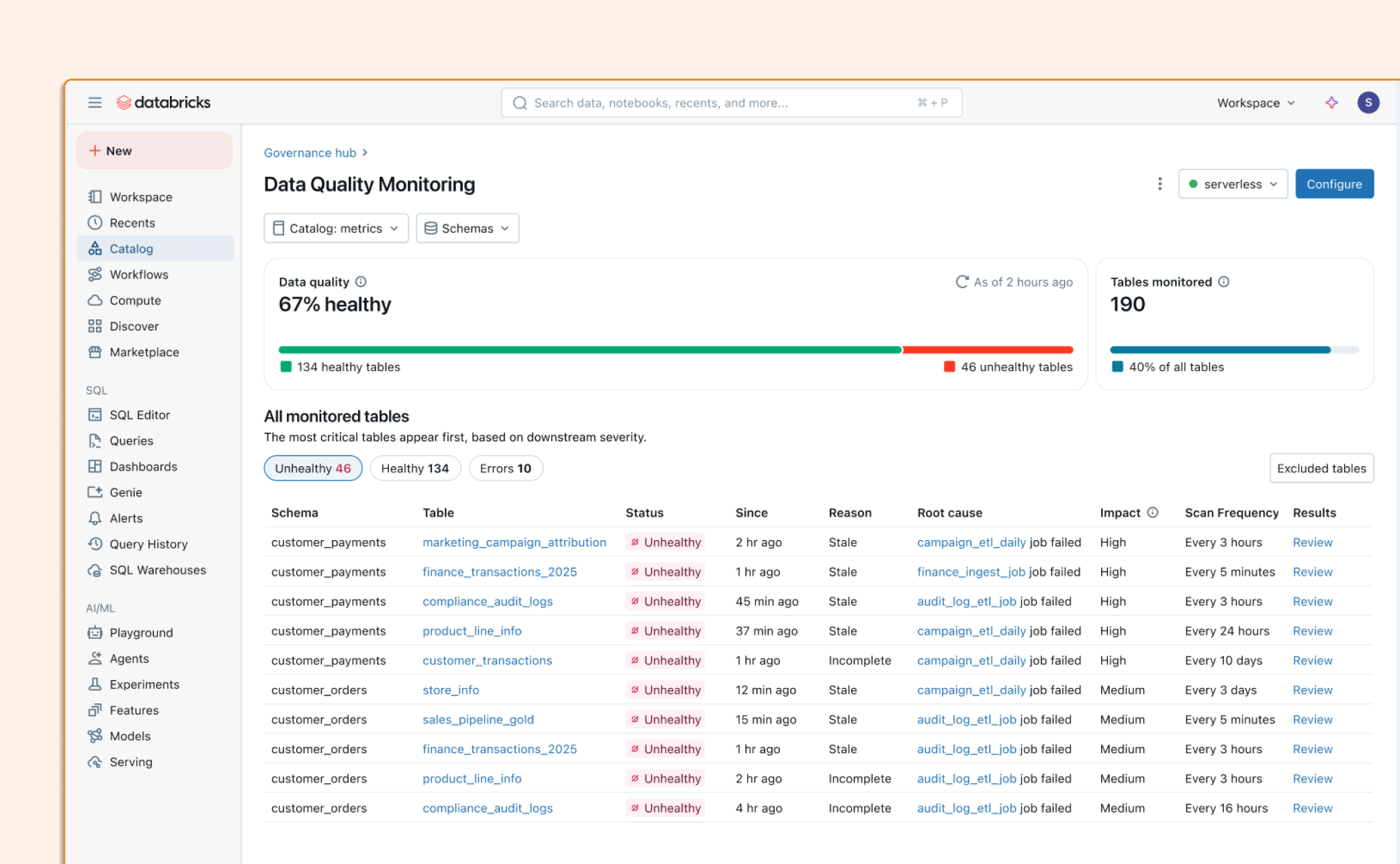
Three practical implications stand out:
Monitor the entire data estate, not just the most critical tables. Schema-level anomaly detection reduces the need for custom checks across every pipeline.
Prioritize issues based on business impact. Unity Catalog lineage and tags help teams focus on what matters most.
Shorten time-to-resolution. By surfacing root causes directly in upstream Lakeflow jobs and pipelines, teams can address issues faster.
This is where data quality becomes a true platform capability and not a heroic effort by a handful of data engineers.
Leadership: make quality someone's job and everyone's habit
A 2026 HBR survey reports the highest-ever percentage of companies (90%) with a Chief Data Officer (CDO). An effective CDO function establishes standards for documentation, lineage, and metric governance; invests in scalable quality platforms; and leads remediation across domains, often partnering with specialists to accelerate foundational work such as metadata management, data modeling, cataloging, and metric rationalization.
But tools alone aren't enough. HBR's research on operational excellence points to culture as the force multiplier — specifically, that the "secret sauce" is making TPS* a way of life for the entire organization, not just a process owned by a single team. For data and AI, this means embedding quality into daily operations through routines, metrics, learning cycles, and consistent leadership standards that persist through organizational change.
A practical call to action (next 90 days)
Assign executive ownership for AI data quality — typically the CDO.
Select AI-critical datasets and require all six pillar elements above.
Implement storage and health indicators using Unity Catalog and agentic monitoring where available.
Standardize metric definitions and enforce reuse across BI and AI use cases.
Create a monthly data quality review: top issues, root causes, prevention actions.
Bottom line: AI quality is not solely a model decision. It is an operational discipline, and it begins with establishing a data quality pillar.
** TPS stands for Toyota Production System, a management and production philosophy focused on continuous improvement and respect for people.*