Cómo migrar tus workloads ETL y EDW de Snowflake a Databricks
Introducción
Estamos observando una tendencia creciente donde Empresas que están sufriendo costos de compute ETL o consumo más altos de lo esperado en Snowflake están migrando a Databricks. Este blog está destinado a una audiencia técnica sobre cómo migrar de Snowflake a Databricks, ya sea para sus workloads de ingeniería de datos/ETL o tanto para la capa ETL/ingeniería de datos como para la capa de consumo final en su EDW.
Recomendamos a los clientes mantener la capa de consumo en Snowflake en la primera fase de migración y migrar primero solo la capa ETL/ingeniería de datos. La capa de consumo final (Gold) en Snowflake puede migrarse en una fase posterior.
Tradicionalmente, las migraciones EDW/ETL de cualquier magnitud suelen ser complejas, largas y desafiantes. Sin embargo, la transición de Snowflake a Databricks es menos compleja en comparación con EDWs onPremise o DataLakes Hadoop por 2 razones principales:
Snowflake es un Data Warehouse nativo en la nube y los pipelines de datos utilizados para hidratar Snowflake se construyeron utilizando tecnologías y principios modernos de ingeniería de datos (como SQL, Python y/o dbt), haciendo que los pipelines de ingeniería de datos sean altamente compatibles con Databricks para migración. Databricks amplía aún más estas capacidades.
Databricks ha invertido y madurado significativamente como EDW y su capa de consumo SQL, lo que hace que la migración sea menos compleja en comparación con Hadoop o EDWs legacy onPremise.
Hemos identificado cinco fases clave para esta migración, que llamamos M5:

Fases de migración M5
Fuente: SunnyData
Data Migration (Migración de Datos)
Data Modeling (Modelado de Datos o Evaluación del Modelo de Datos)
Code Migration (Migración de Código)
Data M-Validation (Validación de Datos y Pipelines)
Report/BI Modernization (Modernización de Informes/BI)
Por otro lado, hemos evaluado la complejidad de cada fase utilizando el símbolo ❅ en honor a Snowflake, que te dará una idea de los desafíos específicos que podrías enfrentar en cada etapa.
Data Migration (Dificultad: ❄️❄️ de ❄️❄️❄️❄️❄️)
Como siempre, el primer paso es la migración de datos. Le asignamos una dificultad de dos copos de nieve (❄️❄️) porque es un proceso estructurado y directo, donde no tienes que manejar alta complejidad en términos de crear código complejo ni es un proceso que genera fricción. La única razón por la que no le asignamos una dificultad menor es porque la fase de Modernización BI puede ser tan fácil como desenchufar y enchufar cuando el esquema no cambia, y eso se puede hacer en minutos.
A pesar de lo anterior, una aclaración muy importante. Hay varias formas de abordar esta fase, pero nos centraremos en tres:
1. Enfoque Moderno
El primero, que es el más reciente y simplificado, implica configurar Snowflake como una fuente de datos federada en Databricks. Esto te permite consultar datos almacenados en Snowflake directamente desde Databricks sin necesidad de exportarlos a otro formato. En lugar de mover físicamente los datos, Databricks puede acceder a ellos a través de consultas, permitiendo una integración más fluida y en tiempo real. Hoy en día es el camino a seguir.
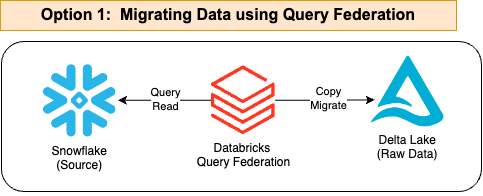
Fuente: Databricks
Aquí hay un código de ejemplo, pero es realmente muy fácil y no tiene complejidad. Consulta el siguiente enlace: https://docs.databricks.com/en/query-federation/snowflake.html:
CREATE TABLE my_databricks_copy AS
SELECT * FROM my_snowflake_table2. Método Tradicional
El segundo enfoque consta de dos pasos y sigue el método tradicional. Si bien es más complejo y puede parecer menos relevante hoy en día, como ingenieros de datos, todavía consideramos que vale la pena explicarlo.
Exportar los datos de Snowflake a Cloud Storage,
Cargar los datos desde Cloud Storage a Databricks.
Exportando Datos de Snowflake a Cloud Storage
Para migrar datos de Snowflake a Databricks, el primer paso es copiar los datos en Cloud Storage (S3, ADLS o GCS) en formato Parquet. Para hacer esto, necesitarás configurar el External Stage y luego usar el comando COPY INTO para descargar los datos de las tablas de Snowflake al almacenamiento en la nube.
En el siguiente ejemplo, usaremos AWS como referencia, pero el mismo procedimiento aplica en Azure y Google Cloud.


Fuente: SunnyData
1. Configuración de External Stage
Un External Stage en Snowflake es un punto de referencia a una ubicación de almacenamiento externa, como un bucket S3, donde se pueden cargar o descargar datos.
Se crea una Storage Integration, que configura la integración de Snowflake con S3 especificando el proveedor de almacenamiento, el AWS role ARN y las ubicaciones permitidas en S3.
CREATE OR REPLACE STORAGE INTEGRATION my_s3_integration
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'S3'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::123456789012:role/MySnowflakeRole'
ENABLED = TRUE
STORAGE_ALLOWED_LOCATIONS = ('s3://my-bucket-name/');STORAGE_PROVIDER: Especifica que el proveedor de almacenamiento es S3.
STORAGE_AWS_ROLE_ARN: Define el ARN del rol IAM en AWS que Snowflake usará para acceder a S3.
STORAGE_ALLOWED_LOCATIONS: Indica la ruta específica del bucket S3 donde se almacenarán los datos.
2. Ahora creamos diferentes external stages que apuntan a ubicaciones específicas en S3, utilizando la integración configurada previamente y especificando el formato de archivo.
CREATE OR REPLACE STAGE my_bronze_stage
URL = 's3://my-bucket-name/bronze/'
STORAGE_INTEGRATION = my_s3_integration
FILE_FORMAT = (TYPE = 'PARQUET');
CREATE OR REPLACE STAGE my_silver_stage
URL = 's3://my-bucket-name/silver/'
STORAGE_INTEGRATION = my_s3_integration
FILE_FORMAT = (TYPE = 'PARQUET');
CREATE OR REPLACE STAGE my_gold_stage
URL = 's3://my-bucket-name/gold/'
STORAGE_INTEGRATION = my_s3_integration
FILE_FORMAT = (TYPE = 'PARQUET');URL: Especifica la ubicación exacta en el bucket S3 donde se almacenarán los datos para cada stage.
STORAGE INTEGRATION: Se refiere a la integración configurada previamente.
FILE FORMAT: Define que los datos se almacenarán en formato Parquet.
2. Descargando Datos Usando COPY INTO
Una vez que los stages están configurados, se pueden descargar datos de las tablas en Snowflake al almacenamiento en S3. Usaremos el comando "COPY INTO":
COPY INTO @my_bronze_stage/customer_data
FROM (SELECT * FROM my_database.public.customer);
COPY INTO @my_silver_stage/order_data
FROM (SELECT * FROM my_database.public.orders);
COPY INTO @my_gold_stage/summary_metrics
FROM (SELECT * FROM my_database.public.orders);La práctica estándar es no aplicar ningún filtro si estamos realizando una migración/decomisión (replicamos todo).
En el ejemplo, estamos copiando todos los datos de cada tabla y siguiendo una estructura tradicional Bronze, Silver y Gold. Algunos clientes pueden tener más capas dependiendo de cómo procesen sus datos. Este proceso de exportación de datos puede ser un poco laborioso, pero es directo.
Con un análisis previo exhaustivo y un mapeo completo de esquemas/tablas, no debería haber complejidad. La parte "laboriosa" puede mitigarse con una herramienta "aceleradora" que permita automatizar parte de este proceso.
3. Migración y/o Reapuntado de Snowflake a Databricks Usando Herramientas como Fivetran
Para usuarios que utilizan herramientas como Fivetran, es aconsejable continuar usándola ya que es una herramienta fantástica que funciona excelentemente dentro del ecosistema Databricks. Entonces, ¿qué deberías hacer? El proceso es sencillo, y una vez más, nos enfrentamos a diferentes opciones que pueden ser complementarias. La primera opción es usar los conectores nativos de Fivetran para Snowflake, que te permiten sincronizar tablas y vistas directamente con Databricks fácilmente. Esta opción es ideal para clientes que desean mantener ciertos workloads en Snowflake mientras aprovechan las capacidades de Databricks para otros procesos.

Source: SunnyData
La segunda opción es migrar completamente los datos a Databricks cambiando el destino en Fivetran. Para hacer esto, necesitas crear un nuevo destino, recrear todas las conexiones a Databricks y ejecutar una sincronización de datos al nuevo destino. Una vez que se completa la sincronización, es esencial validar que la información se haya replicado correctamente y luego actualizar tus aplicaciones de informes y análisis. Finalmente, se desactivan las conexiones al destino anterior (Snowflake).
Es importante destacar que ambas prácticas son totalmente compatibles, y de hecho, este es el enfoque recomendado, representando la realidad de estos tipos de proyectos en la práctica.
Una vez que se completa una de estas fases, tendremos los datos almacenados de forma segura en Cloud Storage.
Leyendo Datos en Databricks
Los datos exportados a Cloud Storage deben leerse desde Databricks, y esto puede hacerse usando 1) Auto Loader, 2) el comando "COPY INTO" de Databricks, o 3) la API Spark Batch Streaming. La elección de qué método usar dependerá del escenario y la estrategia de migración (también hay un componente subjetivo que discutiremos ahora). Por escenario, me refiero a si hay una carga única o no, cargas incrementales, cargas en tiempo real o por lotes, etc., así como mejores prácticas.

Fuente: SunnyData
Por ejemplo, si estamos realizando una migración donde no se seguirán ingiriendo nuevos datos (carga única), podría hacerse usando 'COPY INTO', pero también con Auto Loader o Spark APIs. Muchos ingenieros usan 'COPY INTO' cuando trabajan con miles de registros y Auto Loader cuando procesan millones de registros.
Nota: Si bien hay varias formas de ingerir datos, como usar los propios conectores de Snowflake para Spark, preferimos compartir nuestras recomendaciones basadas en lo que encontramos más eficiente, basándonos en nuestra experiencia personal y las directrices de mejores prácticas de Databricks.
Procedamos con un ejemplo usando código para explicar lo que haremos aquí:
1. Crearemos un Schema (o Database):
CREATE SCHEMA IF NOT EXISTS my_catalog.silver_layer;
y las tablas correspondientes (aquí estoy simulando la creación de 3 tablas):CREATE TABLE IF NOT EXISTS my_catalog.silver_layer.customers;
CREATE TABLE IF NOT EXISTS my_catalog.silver_layer.orders;
CREATE TABLE IF NOT EXISTS my_catalog.silver_layer.line_items;2. Cargaremos los Datos Históricos (usaré COPY INTO y solo lo haré para la primera tabla):
COPY INTO my_catalog.silver_layer.customers
FROM 's3://<some-bucket>/silver/customer/'
FILEFORMAT = PARQUET
FORMAT_OPTIONS ('mergeSchema' = 'true', 'header'='true')
COPY_OPTIONS ('mergeSchema' = 'true');COPY INTO: Copia los datos de los archivos en S3 a las tablas especificadas en el schema silver_layer.
mergeSchema = true: Permite que el esquema de la tabla de destino se ajuste automáticamente si hay diferencias con el esquema del archivo fuente.
header = true: Especifica que la primera fila de los archivos contiene los nombres de las columnas, lo cual es útil para el mapeo correcto de datos.
Realizaremos este proceso con las capas Silver, Gold y cualquier otra que tengamos. No hace falta decir que el código es una simplificación. Al crear una tabla, los nombres de columna, tipos de datos, etc., y cualquier otro ajuste necesario deberán replicarse.
¡Felicidades! Ahora tenemos los datos en el Lakehouse de Databricks.
Data Modeling: (Dificultad: ❄️❄️❄️ de ❄️❄️❄️❄️❄️)
Como indica Databricks en su sitio web, la Arquitectura Medallion proporciona una estructura lógica para organizar datos. De hecho, no tiene que limitarse a las tres capas principales. Cada empresa puede adaptarla a sus necesidades y flujos de trabajo de datos, añadiendo más capas si se considera necesario.

Fuente: SunnyData
En la mayoría de los casos, el modelo de datos no cambia al migrar de una plataforma a otra. Sin embargo, durante la migración, se recomienda mapear el modelo de datos para visualizar cómo se vería el modelo migrado en Databricks. Típicamente, todo seguirá igual, pero esta puede ser una buena oportunidad para evaluar tu estrategia de datos.
Por eso no hemos asignado una calificación de dificultad a esta fase. Usualmente, no habrá que hacer nada aquí, y esta fase será corta. Si estás usando un modelo dimensional (Star Schema), puedes seguir usándolo. Lo mismo aplica si estás usando Data Vault o cualquier otro modelo. Sin embargo, también es bueno saber que cualquier estrategia de datos (como Data Mesh o Data Fabric) es posible en Databricks.
Code Migration: (Dificultad: ❄️❄️❄️❄️ de ❄️❄️❄️❄️❄️)
Esta es la parte más desafiante. Cuando se trata de migrar pipelines, Databricks recomienda usar herramientas nativas siempre que sea posible (como Auto Loader, DLT, Workflows, etc.) para aprovechar al máximo las capacidades de la plataforma.
Sin embargo, si ya estabas usando herramientas como Prophecy o dbt en Snowflake, lo mejor es seguir usándolas, ya que también están bien integradas con Databricks y pueden hacer que la transición sea más suave (simplemente reapunta los pipelines existentes a SQL Warehouse de Databricks).

Source: SunnyData
Para la ingesta de datos, si estabas usando Fivetran en Snowflake, puedes seguir haciéndolo. El único ajuste necesario es reconfigurar los pipelines de ingesta para almacenar datos en formato Delta. De manera similar, si estabas usando Snowpipe, reemplazarlo con Auto Loader en Databricks es una transición sencilla ya que las dos herramientas son conceptualmente equivalentes.

En cuanto al código, Spark se basa en SQL ANSI y ofrece buena compatibilidad con la mayoría de los motores SQL. Sin embargo, todos sabemos que hay diferencias de sintaxis entre diferentes plataformas. Para esto, el mejor enfoque es usar herramientas de código abierto como SQLGlot o aprovechar aceleradores que pueden acelerar el proceso y traducir el código. En SunnyData, hemos trabajado en iniciativas basadas en LLMs para abordar esta necesidad.
Ejemplo de Pipelines (SQL) para Transformación de Datos de nuestra tabla RAW a Silver:
CREATE OR REPLACE TABLE my_catalog.silver_layer.customers AS
SELECT DISTINCT
c.customer_id,
c.customer_name,
c.customer_address,
c.customer_phone,
c.customer_email,
c.account_balance,
c.customer_comment,
n.nation_name AS nation_name,
r.region_name AS region_name,
CASE
WHEN c.market_segment = 'AUTOMOBILE' THEN 'Car Enthusiast'
WHEN c.market_segment = 'BUILDING' THEN 'Construction'
WHEN c.market_segment = 'HOUSEHOLD' THEN 'Home Products'
ELSE 'Other'
END AS customer_segment_group
FROM my_catalog.bronze_layer.customers c
JOIN my_catalog.bronze_layer.nations n ON c.nation_key = n.nation_key
JOIN my_catalog.bronze_layer.regions r ON n.region_key = r.region_key;
A continuación, debemos centrarnos en optimizar el rendimiento del nuevo entorno. Si bien replicar el código tal cual puede ayudar a identificar problemas durante la validación de datos (una práctica recomendada para detectar discrepancias), las tareas de optimización seguirán siendo necesarias como parte de la migración. El hecho de que el código funcione bien en un data warehouse no significa que hará lo mismo en otro. La clave es revisar cuidadosamente las mejores prácticas proporcionadas por Databricks y asegurar que se apliquen. Tomarse el tiempo para optimizar asegurará que la migración sea exitosa y que el sistema funcione de manera eficiente.Data Validation: (Dificultad: ❄️❄️ de ❄️❄️❄️❄️❄️)
Validar que tus tablas migradas contienen los mismos datos que los del sistema legacy puede ser una tarea desalentadora, especialmente cuando tienes un gran número de tablas para migrar. ¡Afortunadamente, te tenemos cubierto! En SunnyData hemos creado herramientas aceleradoras para ayudar a aliviar gran parte de esta carga, comparando automáticamente las tablas de origen y destino con una suite completa de pruebas que van desde la comparación exacta fila por fila hasta distribuciones estadísticas a nivel de columna. Lo que solía ser una tediosa tarea de verificación manual ahora se puede ejecutar repetidamente y ayudarte a construir la confianza necesaria en la corrección de la nueva plataforma.
Report Modernization: (Dificultad: ❄️ de ❄️❄️❄️❄️❄️)
Al migrar datos a una nueva plataforma o sistema, es posible que necesites redirigir informes BI para usar las nuevas fuentes de datos. Uno de los métodos más comunes para lograr esto es probar primero algunos informes de muestra. Si todo se ve bien, entonces simplemente puedes actualizar la fuente de datos o los nombres de tabla en los informes existentes para que apunten a las nuevas ubicaciones de datos.
Hay dos escenarios posibles:
Si la estructura de tablas y vistas (esquema) no ha cambiado: El proceso es bastante directo. Solo necesitas actualizar la configuración en tu herramienta BI para que apunte a la nueva base de datos o tablas. Dado que el esquema sigue siendo el mismo, no deberías necesitar hacer cambios significativos en los informes o dashboards. Es solo cuestión de actualizar la conexión a la nueva base de datos. Además, si mantienes el mismo nombre de dataset en PowerBI, simplemente puedes reemplazarlo y todo seguirá funcionando como de costumbre, asumiendo que todos los demás elementos no han cambiado.
Si la estructura de tablas (esquema) ha cambiado: Este escenario es un poco más complejo. Necesitarás ajustar las tablas o vistas en el nuevo entorno de datos para que coincidan con el esquema esperado por los informes. Esto podría implicar crear nuevas vistas o modificar las existentes para que se alineen con la estructura que requieren los dashboards.
Conclusiones
Migrar de Snowflake a Databricks no es un proceso complejo. En SunnyData, tenemos amplia experiencia en Snowflake, y podemos facilitar la transición completa a Databricks si todavía estás usando Snowflake como tu data warehouse.
Recomendamos encarecidamente descargar la siguiente guía de migración de Snowflake a Databricks: Guía de Migración Snowflake vs. Databricks. Esta guía ofrece una perspectiva más amplia y cubre pasos críticos previos al proceso de migración técnica, como realizar un descubrimiento exhaustivo, evaluación, taller de mapeo, diseño de arquitectura y más.
¡Esperamos ayudarte en tu viaje de migración. Hasta la próxima!