Cómo Migrar Databricks de GCP a Azure o AWS
El concepto de escalabilidad, en mi opinión, no se limita únicamente a la capacidad de una solución para manejar un aumento en la carga de trabajo sin comprometer el rendimiento. También significa que la solución debería ser fácil de gestionar a medida que crece su uso. En el contexto de este blog, la escalabilidad implica que la solución puede extenderse a otras plataformas cloud o facilitar su migración cuando sea necesario.
Para lograr este nivel de flexibilidad, es esencial seguir las mejores prácticas y aprovechar herramientas que automatizan el despliegue y la configuración de componentes. Databricks es una plataforma agnóstica respecto a la nube, pero para poder pivotar entre proveedores cloud, el uso de aceleradores como Terraform es crucial, ya que agiliza el proceso de despliegue en el nuevo destino.
¿Qué motivaciones podríamos tener para dejar un proveedor cloud?
Aunque cambiar de proveedores cloud no es muy común hoy en día (puede volverse más frecuente en el futuro a medida que aumente la competencia entre proveedores cloud), hay ciertas situaciones que podrían motivar tal cambio. En este artículo, mencionaremos algunos de los escenarios más comunes:

Competitividad de costos: Un proveedor puede volverse menos competitivo con el tiempo. Por ejemplo, Databricks tiende a ser más rentable en Azure y AWS.
Cambios estratégicos: Un nuevo director puede preferir un proveedor cloud diferente o aprovechar incentivos y beneficios ofrecidos por otro proveedor, como créditos.
Multi-cloud y recuperación ante desastres: Puede haber una necesidad de una configuración multi-cloud con capacidades de alta disponibilidad y recuperación ante desastres.
Cómo abordar una migración entre proveedores cloud
En este blog, nos enfocaremos específicamente en la migración y replicación de recursos de Databricks, como clusters, jobs, repositories y otros. Si bien tocaremos brevemente aspectos relacionados con la migración de datos, la gestión de dependencias con servicios externos e integraciones, así como la configuración de permisos y seguridad, cubriremos estos temas a alto nivel, ya que han sido discutidos en detalle en otros blogs.
Tampoco profundizaremos en estrategias de negocio o aspectos de gestión de proyectos, pero podemos resumir los principios clave con una recomendación para adoptar un enfoque gradual. En lugar de intentar manejar toda la migración a la vez, es más efectivo dividir el proceso en fases manejables, enfocándose en casos de uso específicos y migrando cada componente progresivamente. Esto permite que se realicen ajustes y optimizaciones en cada etapa antes de pasar a la siguiente.
Para abordar una migración de cloud a cloud o implementar un entorno multi-cloud, es crucial utilizar herramientas que automaticen el despliegue de infraestructura. Terraform es altamente recomendado en el ecosistema de Databricks por su capacidad para gestionar la infraestructura como código.

Adicionalmente, ofrece soluciones preconfiguradas que optimizan este proceso, como el Databricks Resource Exporter, que simplifica la exportación y migración de recursos.
Databricks Terraform Resource Exporter
Es una herramienta que ayuda a exportar y migrar todos los recursos de un Workspace de Databricks de un CSP (Cloud Service Provider) a otro. Esta herramienta genera archivos de configuración de Terraform (.tf) y un script import.sh para facilitar el proceso de importación. Ahorra mucho tiempo y reduce la necesidad de tareas manuales. Sin embargo, hay tres consideraciones importantes a tener en cuenta sobre este acelerador:
El proceso debe repetirse para cada workspace de Databricks que quieras migrar.
Es importante notar que la herramienta todavía está en fase experimental.
Se requieren algunas tareas manuales, como se explica a continuación.
Esencialmente, el exportador de Terraform de Databricks escanea todos los recursos existentes en el workspace, creando un archivo .tf para cada tipo de recurso (por ejemplo, users.tf, compute.tf, workspace.tf, secrets.tf, access.tf, etc.). Cada archivo .tf almacena toda la información asociada con las configuraciones existentes.
En la siguiente imagen, podemos visualizar el proceso de escaneo y generación:
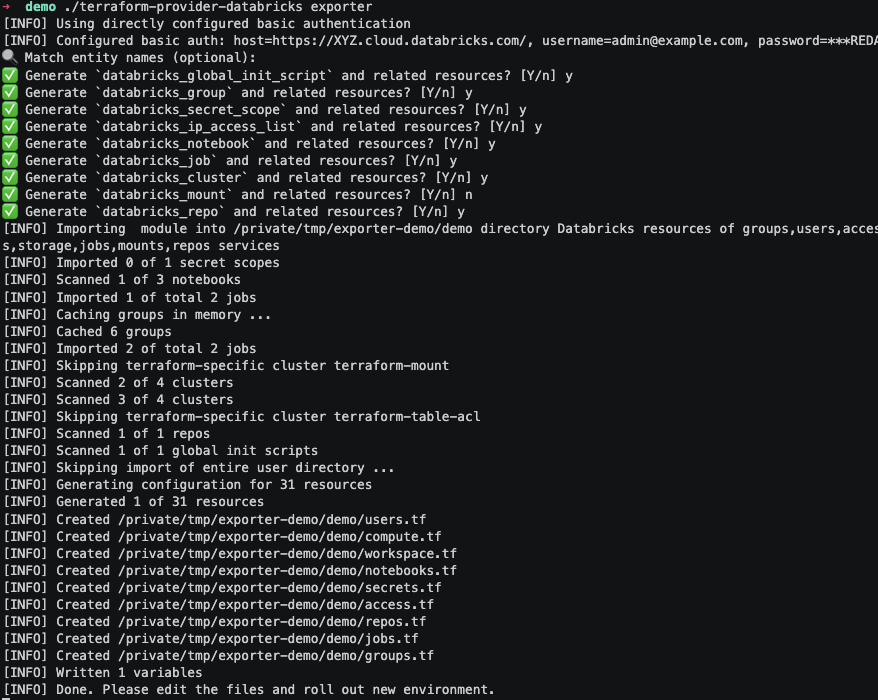
Después, cada archivo debe ajustarse manualmente para reflejar las diferencias entre proveedores, como nombres de instancias o la disponibilidad de características específicas en cada región. Por ejemplo, una instancia de compute en GCP tiene un nombre diferente en Azure o AWS, y ciertas funcionalidades, como SQL Serverless, no están disponibles en todas las regiones, incluso dentro del mismo CSP.
En SunnyData, utilizamos aceleradores basados en LLM para automatizar y agilizar estos ajustes manuales requeridos en los archivos .tf. Esto nos permite optimizar aún más el proceso de migración, reduciendo el tiempo necesario para afinar configuraciones y mejorando la eficiencia al gestionar y migrar múltiples workspaces de Databricks.
Una vez que se han realizado los ajustes necesarios, los archivos .tf modificados pueden aplicarse al nuevo proveedor cloud para recrear todos los recursos de Databricks. El script import.sh simplifica el proceso ejecutando múltiples comandos de importación de Terraform, ahorrando tanto tiempo como dinero.
Otros Aspectos Técnicos de la Migración
Para realizar una migración completa de Databricks, se deben considerar varios componentes más allá de la infraestructura misma. Algunos de estos incluyen:
a > Datos Almacenados
Los datos almacenados en Databricks (que típicamente están respaldados por GCS, S3 o ADLS) deben migrarse por separado. Esto puede hacerse usando métodos como:
AzCopy, AWS CLI o herramientas similares para mover datos entre nubes.
Usar una herramienta aceleradora de ETL para facilitar la transferencia de grandes conjuntos de datos (*).
*Delta Live Tables (DLT) Pipelines: Los pipelines DLT requieren consideraciones especiales durante la migración. Al migrar estos pipelines entre proveedores cloud, es esencial asegurar que el estado y los checkpoints se gestionen adecuadamente para prevenir pérdida de datos o inconsistencias.
Para lograr una migración exitosa de pipelines de streaming DLT, puedes:
Reiniciar el pipeline desde el principio: Esto asegura que todos los datos se procesen nuevamente, aunque puede ser lento y consumir muchos recursos si el volumen de datos es grande.
Ajustar la ejecución inicial para usar el snapshot actual: Configurar el pipeline para comenzar a procesar desde el estado más reciente, evitando la necesidad de reprocesar toda la historia de datos. Esto implica ajustar checkpoints y asegurar que las fuentes de datos estén sincronizadas en el nuevo entorno.
Mover datos manualmente utilizando scripts.
b > Conexiones de Servicios Externos
Necesitarás revisar y ajustar conexiones con servicios externos (como bases de datos, APIs o sistemas de mensajería). Esto incluye actualizar credenciales, configuraciones de autenticación y endpoints de API/servicio que pueden cambiar entre nubes.
c > Modelos MLflow
Los modelos almacenados en MLflow dentro de Databricks deben exportarse e importarse manualmente para completar la migración. Aunque los recursos de Terraform como databricks_mlflow_experiment, databricks_mlflow_model y databricks_mlflow_webhook ayudan a gestionar y migrar algunos aspectos de experimentos y modelos, no manejan automáticamente los artefactos subyacentes (como modelos entrenados o conjuntos de datos). Estos deberán migrarse por separado.
d > Ajustes de Metadatos de Clusters
Como se mencionó anteriormente, es importante reiterar que los archivos deberán adaptarse a las características del nuevo entorno. Esto incluye revisar y ajustar metadatos de clusters, como configuraciones de auto-scaling, configuraciones de almacenamiento y políticas de auto-shutdown. Cada uno de estos elementos debe verificarse para asegurar que las configuraciones sean compatibles con los recursos disponibles en el nuevo entorno cloud.
e > Seguridad y Permisos
Mientras que el exportador de Terraform maneja algunos aspectos de la migración de permisos y seguridad, como ACLs y políticas de acceso integradas con IAM, las configuraciones avanzadas (como roles personalizados o configuraciones de red como VPCs, subnets y firewalls) deberán revisarse y ajustarse manualmente para asegurar que estén adecuadamente adaptadas al nuevo entorno cloud.
f > Auditoría y Monitoreo
Para recursos como Azure Monitor, CloudWatch o Google Cloud Logging, estos deberán reconfigurarse en el cloud de destino, ya que no son específicos de Databricks sino que dependen de la plataforma cloud en la que operan. De manera similar, los umbrales de costo y otras configuraciones estándar de infraestructura cloud deberán restablecerse.
Conclusiones
Migrar entre diferentes plataformas cloud, incluso cuando se usa la misma plataforma como Databricks, siempre presenta un desafío que requiere una planificación cuidadosa y una gestión adecuada. Sin embargo, es un proceso factible y puede ser altamente beneficioso, especialmente en situaciones donde se han adquirido créditos cloud o deben consumirse dentro de un plazo específico.
Con el tiempo, los escenarios multi-cloud se volverán cada vez más comunes, y estamos seguros de que contenido como este blog proporcionará un valor significativo a aquellos que enfrentan estos desafíos.