Redshift a Databricks - Parte 2: Guía de Implementación Técnica
Este artículo es la segunda entrega de nuestra serie sobre la migración de Redshift a Databricks. Si estás comenzando este viaje, te recomendamos encarecidamente leer el primer blog antes de sumergirte en este, ya que proporciona el contexto esencial, describe los pasos iniciales de la transición y destaca los beneficios de hacer el cambio.
Nota: La Parte 1 está orientada a audiencias empresariales o aquellos que no ejecutarán directamente la migración técnica. Puedes encontrar la Parte 1 aquí: Redshift a Databricks: Por qué y cómo comenzar.

Fuente: SunnyData
Como discutimos en la Parte 1, migrar EDWs y procesos ETL de sistemas tradicionales on-premises a la nube es a menudo un proceso complejo y que consume mucho tiempo. Sin embargo, migrar de Amazon Redshift a Databricks es comparativamente más sencillo, ya que los datos ya están en la nube, eliminando muchos de los desafíos asociados con las transiciones on-premises.
En el blog anterior, exploramos Redshift y Databricks, evaluando sus fortalezas y debilidades para establecer las bases para el viaje de migración. Con esta comprensión en su lugar, comenzamos el primer paso esencial: la fase de descubrimiento.
En este artículo, revisitaremos esta fase inicial, ampliando lo que hemos discutido previamente (omitiendo aceleradores y temas ya cubiertos) para ayudar a recontextualizar a los lectores en las etapas de migración y proporcionar información adicional.
Del Descubrimiento a la Acción: Fase 1
Esta fase implica realizar evaluaciones de migración en profundidad para entender los requisitos específicos y las complejidades involucradas. Durante el descubrimiento, la recopilación de información clave es crucial para guiar eficazmente el proceso de migración. Antes de mover cualquier dato o workload, estas evaluaciones proporcionan una visión integral del panorama de migración, permitiendo decisiones informadas en cada etapa.
Para simplificar el proceso de recopilación de información, recomendamos utilizar aceleradores, que pueden acelerar las evaluaciones. Sin embargo, independientemente de las herramientas o métodos utilizados, el objetivo esencial sigue siendo el mismo: obtener los siguientes insights críticos.
Pasos Clave en la Fase de Descubrimiento
Ahora que hemos establecido la importancia de la fase de descubrimiento, profundicemos en los pasos clave que guiarán eficazmente tu proceso de migración.
1. Identificar Workloads y Catalogar la Complejidad
Primero, es crucial identificar los tipos de workloads involucrados en tu configuración actual, tales como:
ETL Processes: Operaciones de Extracción, Transformación y Carga que mueven y transforman datos.
Business Intelligence (BI): Herramientas analíticas y sistemas de informes.
Data Ingress/Egress: Datos que fluyen hacia y desde tus sistemas.
Entender estos workloads y sus tamaños a través de diferentes warehouses y bases de datos te ayuda a comprender el volumen y la naturaleza de las tareas a migrar. Esto forma la base para estimar el esfuerzo y los recursos requeridos.
Nota: Una buena práctica es categorizar workloads por complejidad y propósito, permitiéndote priorizar casos de uso que se alineen con las necesidades del negocio y establecer un plan de migración que aumente gradualmente en dificultad. Este enfoque puede evitar abordar los workloads más complejos al inicio y se centra en entregar resultados impactantes al inicio del proceso.

TIP 1: Posicionándote para el Éxito
Recopilar insights de estas evaluaciones te posiciona para el éxito al clarificar la complejidad y el alcance del esfuerzo de migración. Esta fase preparatoria te permite tomar decisiones basadas en datos, priorizar workloads que maximicen el valor de negocio y asignar recursos eficientemente.
2. Evaluación de Datos
A continuación, es esencial evaluar el alcance, la estructura y el rendimiento de los datos y consultas a migrar. Una evaluación integral de datos ayuda a priorizar workloads críticos, optimizar la planificación de migración y anticipar desafíos potenciales:
Determinar Datos y Workloads Esenciales: Identifica los datos, tablas y workloads cruciales para tus operaciones y priorízalos para la migración. Este paso está conectado con el anterior, pero es importante destacar lo importante que es entender el modelo de datos actual, las tablas involucradas, etc.
Catalogar Tablas y Estructura: Identifica y cataloga tablas a través de cada base de datos, tomando nota de dependencias, relaciones y cualquier complejidad estructural (como altos niveles de normalización) que pueda requerir transformación y optimización adicional.
Evaluar Volumen y Calidad de Datos: Mide el volumen de datos tanto a nivel de tabla como de workload para estimar las necesidades de almacenamiento y procesamiento en el nuevo entorno. En una migración de Redshift a Databricks dentro de AWS, los datos ya están en la nube, por lo que la logística de migración de datos puede que ni siquiera sea necesaria. Sin embargo, es esencial enfatizar las verificaciones de calidad de datos a lo largo del proceso de migración, ya que estas aseguran un rendimiento confiable y precisión en la nueva configuración.
Evaluar Consultas Asociadas: Evalúa las consultas relacionadas con cada conjunto de datos, evaluando su frecuencia y complejidad.
Analizar el Rendimiento de Consultas y Patrones de Uso: Identifica consultas de alta frecuencia y analiza su estructura, toma nota de la programación y frecuencia de workloads (como trabajos ETL, informes y transferencias de datos), e identifica los tiempos de uso máximo para optimizar la asignación de recursos y el diseño de programación en Databricks.
Tener un alcance preciso permite una planificación más precisa y ayuda a anticipar desafíos potenciales que puedan surgir durante la migración.
TIP 2: Mantente Adaptable
Es importante tener en cuenta que tu plan de migración inicial puede necesitar ajustes basados en descubrimientos realizados durante esta fase. Mantener un enfoque adaptable asegura la alineación con las realidades de tus datos e infraestructura, conduciendo en última instancia a una migración más exitosa.
3. Mapear Dependencias Upstream y Downstream
Mapear las dependencias dentro de tu ecosistema de datos es otro paso crítico:
Technologies: Identifica software y herramientas que interactúan con tus datos.
Applications: Toma nota de cualquier sistema que dependa o alimente tus data warehouses.
Connected Processes: Entiende los flujos de trabajo que podrían verse afectados.

Dado que muchos componentes que dependen de Redshift pueden ser reutilizables (dependiendo de la estrategia de migración definida, ya sea un lift-and-shift directo o una refactorización más extensa), hacer coincidir estos componentes con precisión es esencial. Este mapeo será revisitado en la próxima fase para confirmar la compatibilidad y refinar aún más los planes de integración.
4. Revisar Protocolos de Seguridad
La seguridad es primordial durante la migración, especialmente al moverse de Redshift a Databricks dentro de AWS. Las acciones clave incluyen:
Evaluar tu configuración de seguridad actual: Comienza identificando vulnerabilidades potenciales en la configuración actual de Redshift, revisando roles de usuario, permisos y configuraciones de red para detectar cualquier brecha de seguridad.
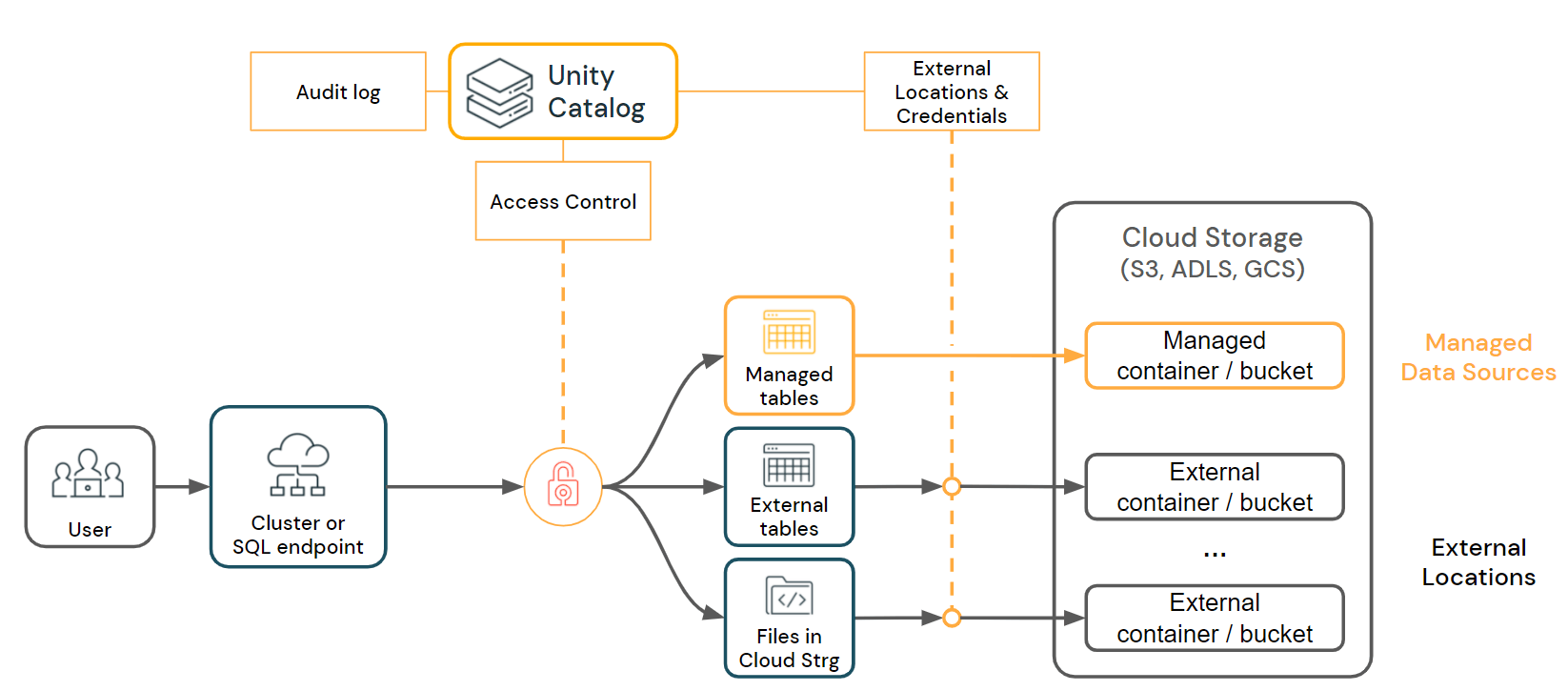
Alinear con los Requisitos de Seguridad de Databricks: Para asegurar la continuidad de seguridad, adapta roles de usuario y permisos mientras transicionan a Databricks, implementando RBAC y MFA si aún no están en su lugar. Alinea políticas de gobernanza de datos de Redshift a Databricks configurando clasificación de datos, seguimiento de linaje y registro de accesos, lo que ayuda a mantener la integridad de los datos y la trazabilidad. Una buena práctica es usar Unity Catalog desde el principio en Databricks.
Asegurar el cumplimiento de estándares regulatorios y mejores prácticas de la industria: Para mantener el cumplimiento regulatorio, verifica la alineación con estándares específicos de la industria como GDPR, HIPAA y SOC 2, adaptando políticas en Databricks para cumplir estos requisitos. Si es aplicable, implementa o verifica características de enmascaramiento y anonimización de datos para salvaguardar efectivamente la información sensible.
Esto proporciona una base segura en el nuevo entorno y construye confianza con las partes interesadas.
5. Estimar Costos de Infraestructura
Estimar cuidadosamente los costos de infraestructura para la migración asegura que los recursos se asignen efectivamente, y que la inversión se alinee con los retornos esperados. Consideraciones importantes incluyen:
Anticipar necesidades presupuestarias para asignar recursos efectivamente: Para asignar recursos eficientemente, evalúa los costos de almacenamiento y cómputo en Databricks. Las necesidades de almacenamiento deberían ser similares, con cierto margen para conjuntos de datos duplicados o transformados. Evalúa recursos de cómputo basados en el uso actual de Redshift, ajustando para demandas de workload y ganancias potenciales de rendimiento de Databricks.
Justificar la inversión alineando costos con beneficios esperados: Un análisis bien planificado de costo-beneficio es crucial para demostrar el retorno de inversión para la migración. Compara los costos proyectados en Databricks con los beneficios esperados para justificar el gasto.
Planificar para escalabilidad para acomodar crecimiento futuro: Para asegurar que la migración soporte el crecimiento futuro del negocio, planifica para escalabilidad tanto en recursos de almacenamiento como de cómputo. Estima tendencias de crecimiento de datos y planifica cómo las capacidades de escalado flexible de Databricks pueden satisfacer estas necesidades en expansión sin reconfiguraciones importantes.
Entender el aspecto financiero asegura que los recursos estén alineados con los objetivos de migración y que el proceso entregue valor significativo a la organización.
TIP3: Aprovecha las Herramientas de Databricks como Unity Catalog, Serverless y DLT.

Maximiza la eficiencia de costos, rendimiento y ROI implementando mejores prácticas de principio a fin. Herramientas clave de Databricks, como Unity Catalog para gobernanza de datos, Serverless para asignación dinámica de recursos y Delta Live Tables (DLT) para pipelines de datos automatizados, pueden optimizar tu migración y simplificar operaciones a través de la plataforma.
Puedes lograr ahorros significativos de costos aplicando mejores prácticas e implementando estrategias de FinOps, que ayudan a gestionar eficientemente el gasto en la nube y maximizar el valor de tu inversión.
Diseñando la Arquitectura Objetivo: Fase 2
Una vez que la fase inicial de descubrimiento está completa, es hora de planificar la migración de Amazon Redshift a Databricks. Esta fase es crucial porque los entornos de Redshift a menudo están integrados con varios servicios AWS y herramientas de terceros, requiriendo una evaluación cuidadosa de cada componente. Dependiendo de la estrategia de migración definida, varios servicios existentes pueden ser reutilizables, eliminando la necesidad de reconstruir toda la infraestructura desde cero.
Diferentes enfoques pueden considerarse aquí, como un lift & shift sencillo, refactorización de aplicaciones, o casos más simples donde solo se requiere desconexión y reconexión, como con herramientas BI como Power BI, que pueden operar "sin grandes modificaciones". La elección de estrategia depende de múltiples factores, incluyendo el nivel de dependencia de los sistemas actuales, objetivos de modernización y el rendimiento deseado en el nuevo entorno.
Databricks recomienda aprovechar completamente sus capacidades, incluyendo herramientas como Unity Catalog para gobernanza de datos, Delta Live Tables (DLT) para pipelines de datos automatizados y Autoloader para ingesta de datos, por ejemplo. Sin embargo, en algunos casos, herramientas de terceros, como AWS Glue para ingesta de datos o Fivetran, también pueden integrarse y reutilizarse según sea necesario, dependiendo de la estrategia de migración.
El objetivo de esta fase es diseñar una hoja de ruta de modernización clara y personalizada. Comparar los diagramas arquitectónicos actuales y futuros es esencial para identificar los pasos intermedios necesarios. Por ejemplo, durante la migración, puede ser necesario ejecutar pipelines de transformación de datos tanto en Redshift como en Databricks para mantener la consistencia y minimizar el tiempo de inactividad. En tales casos, será necesario desarrollar soluciones para sincronizar datos, asegurando que los sistemas externos continúen operando sin problemas.
Para dar forma a esta estrategia de manera efectiva, es necesario anticipar contratiempos potenciales y delinear cómo serán abordados. Este análisis estructurado debería incorporarse al plan de migración, detallando los pasos específicos para permitir una transición sin problemas con mínimas interrupciones. Esta fase es donde la estrategia de migración realmente toma forma, definiendo los procesos técnicos y operativos necesarios para ejecutar el cambio de manera efectiva.

Usando los insights recopilados en la Fase 1, mapearemos cada característica de Redshift a su equivalente en Databricks, asegurando una transición sin problemas sin pérdida de funcionalidad esencial. La tabla a continuación destaca cómo las características clave entre Amazon Redshift y Databricks se alinean, proporcionando una vista clara de componentes compatibles para migración.
Vale la pena señalar que esta tabla, compartida por Databricks, está diseñada para comparar Redshift con Databricks usando la suite completa de componentes de Databricks. Sin embargo, como mencionamos anteriormente, ciertos elementos de Redshift o herramientas de otros proveedores pueden seguir siendo viables dependiendo de la estrategia de migración. Estas elecciones, aunque importantes, están fuera del alcance de este blog, ya que una discusión extensa sobre cada componente posible podría hacer que este artículo sea difícil de seguir.
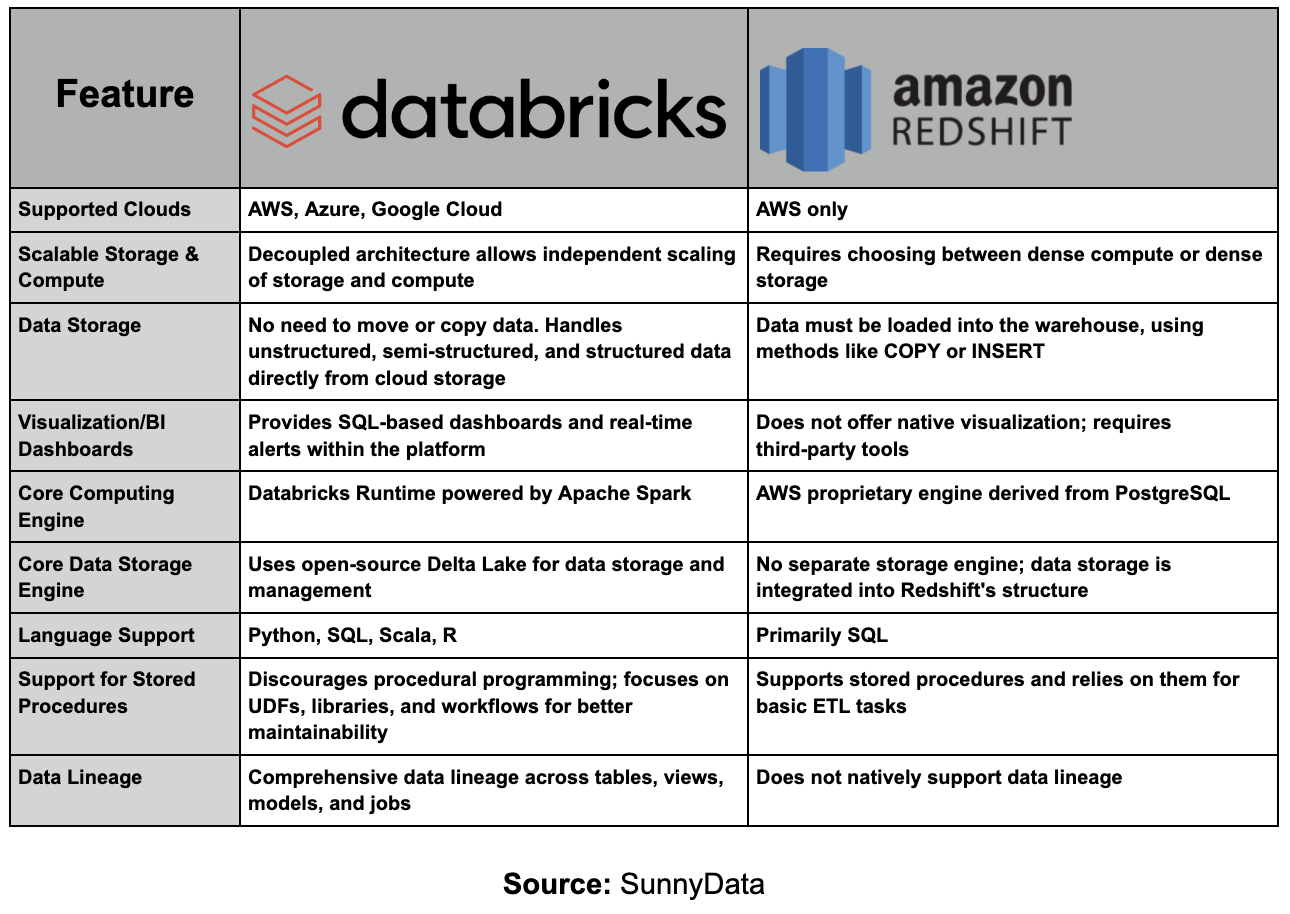
Al final de esta fase, tendremos una comprensión clara del alcance y la complejidad de la migración, permitiéndonos crear un plan de migración preciso y una estimación de costos.
Migración de Datos: Fase 3
Aunque los datos ya están en la nube, esto no significa que no haya una fase de migración de datos involucrada. El primer paso es crear workspaces para establecer los entornos donde estaremos trabajando. Como mejor práctica, generalmente se recomienda configurar múltiples workspaces, que pueden organizarse por entorno (por ejemplo, desarrollo, staging, producción, QA) para facilitar un flujo de trabajo estructurado y asegurar la integridad de los datos a través de diferentes etapas de desarrollo.
Alternativamente, los workspaces pueden estructurarse por unidades de negocio (como marketing, finanzas, ventas) o incluso diseñarse para soportar un enfoque de data mesh, donde los datos se descentralizan en dominios distintos. Este método permite a los equipos mantener el control sobre sus datos mientras fomenta la colaboración interfuncional. Definir estos workspaces desde el principio proporciona una base bien organizada para el proceso de migración y asegura la alineación con las necesidades del negocio y las prácticas de gobernanza.
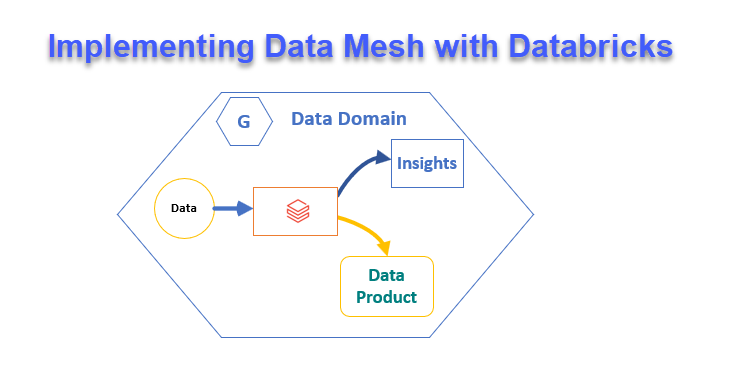
Con los workspaces configurados, estamos un paso más cerca de comenzar la migración gradual de datos y metadatos, siguiendo el plan de migración definido por fases. Es esencial tener en cuenta que Amazon Redshift utiliza un formato propietario, que requiere un manejo cuidadoso.
Antes de comenzar la migración actual, necesitaremos establecer cómo debería organizarse la estructura de datos en Databricks. Las preguntas clave incluyen si mantener la misma jerarquía de catálogos, bases de datos, esquemas y tablas en el destino, o si deben hacerse ajustes para simplificar u optimizar la estructura.
Adicionalmente, deberíamos considerar cualquier limpieza de datos necesaria, como eliminar conjuntos de datos duplicados o reorganizar la huella de datos de Redshift para alinearse mejor con la arquitectura de Databricks. Una vez que estas decisiones estructurales estén finalizadas, la migración de datos puede proceder sin problemas. Como guía general, recomendamos minimizar los cambios de esquema durante la migración; con la función de Evolución de Esquema de Delta, las modificaciones de esquema a menudo se implementan mejor después de que los datos se cargan en Delta, permitiendo ajustes graduales con el tiempo.
Migración de Esquema
Antes de mover tablas a Databricks, es esencial configurar el esquema por adelantado. Si tienes scripts DDL existentes, puedes adaptarlos con ajustes menores para alinear los tipos de datos con los requisitos de Databricks.

Modelado de Datos en el Lakehouse
Los datos en Redshift a menudo se originan de fuentes como Amazon S3, Amazon EMR o Amazon DynamoDB y siguen modelos de datos específicos, como modelos dimensionales o data vault. Estos pueden implementarse en la arquitectura Lakehouse de Databricks con incluso mejor rendimiento usando Delta Lake. La arquitectura medallion (capas Bronze, Silver, Gold) estructura los datos en etapas que mantienen la calidad y organización de los datos.
El proceso de migración típicamente involucra mover tablas EDW a las capas Bronze, Silver y Gold de Delta Lake. Este enfoque por fases preserva la calidad y estructura de los datos, con pipelines de datos incrementales poblando cada capa según sea necesario. Cualquier backfilling necesario puede realizarse entonces para asegurar la completitud de los datos. Para guía adicional sobre modelado de datos en este contexto de migración, consulta nuestro blog sobre Migración a Snowflake, que cubre principios de modelado de datos que aplican igualmente aquí.

Cargar Datos de Redshift a Databricks
Para migrar tablas Gold, Databricks ofrece varios enfoques probados:
Usando el Comando UNLOAD de Amazon Redshift: Exporta datos de Amazon Redshift al almacenamiento en la nube en formato Parquet. Desde ahí, carga los datos en DDL usando herramientas como Auto Loader, el comando COPY INTO, o APIs de Spark batch/streaming.
Usando el Conector Spark Amazon Redshift: Conéctate directamente a Redshift y lee datos en un DataFrame de Spark. Este DataFrame puede entonces guardarse como una tabla Delta Lake, proporcionando integración perfecta con Databricks.
Usando Partners de Ingesta de Datos: Utiliza opciones de Databricks Partner Connect, como Hevo, para automatizar la migración de datos con configuración sin código. Estas herramientas ofrecen gestión de esquema integrada, alta disponibilidad y autoescalado para simplificar el proceso.
Consideraciones Clave: Al migrar esquema, considera los estilos de distribución y claves de ordenación de Redshift, que tienen estrategias de optimización equivalentes en Databricks, como Liquid Clustering. Asegura la compatibilidad del esquema fuente, especialmente para tipos de columna, para evitar casting innecesario. Mantener esquemas sincronizados durante la transición es crucial; usar una herramienta MDM ayuda a gestionar cambios de esquema a través de ambas plataformas efectivamente.
Migración de Código: Fase 4
Migrar pipelines de datos de Amazon Redshift a Databricks involucra varios componentes clave:
Migración del modelo de cómputo
Migración de orquestación
Migración de Source/Sink
Migración y refactorización de consultas
Para realizar efectivamente esta migración, es crítico entender la vista completa de los pipelines, desde las fuentes de datos hasta la capa de consumo, incluyendo aspectos de gobernanza.
Migración del Modelo de Cómputo
Databricks ofrece mayor flexibilidad en opciones de cómputo para diferentes necesidades de pipeline, permitiendo que los recursos se adapten a necesidades específicas de procesamiento de datos:


Tipos de cómputo en Databricks:
All-purpose: Clusters que soportan múltiples lenguajes y pueden estar siempre activos o con reglas de auto-terminación.
Jobs: Cómputo efímero para tareas específicas que se activa solo mientras el trabajo está ejecutándose.
DBSQL, DLT y Serverless: Opciones para cómputo avanzado en data warehousing y procesamiento de consultas.
Consejos de uso:
Compartir clusters: Cuando las tareas usan los mismos datos, compartir la caché del cluster puede mejorar el rendimiento.
Aislar clusters: Para tareas que consumen muchos recursos, se recomiendan clusters dedicados para evitar cuellos de botella.
Databricks proporciona recursos extensos sobre seleccionar el tipo de cómputo correcto para varios escenarios, haciendo sencillo alinear recursos de Databricks con aquellos usados en Amazon Redshift. Esta información puede simplificar el proceso de hacer coincidir y optimizar recursos de cómputo durante la migración.
Migración de Orquestación
La migración de orquestación en el contexto de pipelines ETL se enfoca en transferir mecanismos de programación y control de flujo para asegurar que las tareas se ejecuten en el orden correcto y en los momentos apropiados en el nuevo entorno de Databricks. Esto es esencial para coordinar la ingesta de datos, integración y generación de resultados a través de workflows.
En Amazon Redshift, la orquestación a menudo se gestiona a través de servicios como AWS Glue, AWS Data Pipeline, AWS Step Functions y AWS Lambda. Alternativamente, es común usar Apache Airflow, scripts personalizados basados en Python, o herramientas de terceros como Fivetran. Cada uno de estos métodos permite definir y controlar la ejecución de tareas a través de diferentes etapas de un pipeline ETL.
Opciones en Databricks:
Usar Databricks Workflows para reingeniería de la capa de orquestación, permitiéndote aprovechar herramientas como Delta Live Tables.
Usar herramientas externas como Airflow, simplemente traduciendo consultas SQL de Redshift a Spark SQL y manteniendo la orquestación existente.
Recomendación: Opta por Databricks Workflows para lograr integración mejorada, simplicidad y trazabilidad. Si estás usando herramientas de terceros como Fivetran, puedes continuar aprovechándolas dentro del entorno de Databricks, integrándose perfectamente con tus workflows.
Migración de Data Source/Sink
En Amazon Redshift, los patrones de ingesta a menudo utilizan S3 como almacenamiento intermedio. En Databricks, las configuraciones de fuente y destino de datos se adaptan para aprovechar Delta Lake y las capacidades nativas de la plataforma:
Conexiones de origen:

Los pipelines de ingesta con herramientas como Fivetran pueden configurarse para apuntar a Delta Lake en Databricks.
Ingesta directa desde S3 usando Databricks Auto Loader o APIs de Spark DataFrame.
Integraciones Spark para datos de streaming: Los pipelines que involucran datos de streaming, como aquellos de Amazon Kinesis, pueden transformarse usando integraciones Kafka dentro de Spark, soportando procesamiento robusto en tiempo real.

Conexiones de destino:
Las herramientas de ingesta deberían ajustarse para producir datos en formato Delta Lake en lugar del formato nativo de Redshift, permitiendo compatibilidad y rendimiento óptimos dentro de Databricks.
Migración y Refactorización de Consultas
La migración de consultas involucra tanto consultas de transformación de datos como consultas analíticas ad hoc. Aquí hay un desglose de los principales aspectos a considerar:
>> Migración de consultas SQL:
Conversión Automatizada: Usa una herramienta Convertidora para automatizar la conversión de SQL de Redshift a Spark SQL, agilizando el proceso de migración. Aprovechar un acelerador, como aceleradores estáticos comerciales o soluciones avanzadas como el acelerador potenciado por LLM de SunnyData, puede mejorar aún más la eficiencia y precisión en transformaciones SQL complejas.

Métodos Alternativos: Aunque es posible, el desarrollo de scripts personalizados o la conversión manual son menos recomendados debido al mayor esfuerzo y riesgo de inconsistencias - (no recomendado)
>> Migración de procedimientos almacenados:
Databricks no tiene un objeto específico para procedimientos almacenados, pero pueden crearse en Databricks Workflows como tareas.
Transforma patrones SQL de Redshift a Databricks SQL o PySpark para mantener funcionalidad como declaraciones condicionales y manejo de excepciones.
>> Consideraciones para objetos de base de datos comunes y patrones SQL:
UDFs de Python pueden migrarse fácilmente, mientras que UDFs de Java necesitan convertirse a SQL o Python.
CTEs recursivas y transacciones multi-declaración requieren soluciones personalizadas en PySpark y Delta Lake.
Validación de Migración

La validación es crítica para asegurar que los datos en Amazon Redshift y Databricks coincidan después de la migración. Dado que el número de tablas migradas puede ser muy alto, la comparación manual de valores es inviable. Para esto, se recomienda implementar un marco de pruebas automatizado que compare datos en ambas plataformas. En SunnyData tenemos un acelerador para la validación y comparación de datos automáticamente que ahorra mucho tiempo.
Puntos de validación:
Verificación de existencia de tablas: Comprobar que todas las tablas requeridas se hayan creado en Databricks.
Conteo de filas y columnas: Comparar el número de filas y columnas en cada tabla en ambas plataformas.
Suma de columnas numéricas: Calcular y comparar la suma de valores en columnas numéricas para asegurar consistencia.
Conteo de valores distintos en columnas de texto: Evaluar y comparar el número de valores únicos en columnas de texto.
Ejecutando pruebas paralelas:
Ejecutar pipelines en paralelo en ambas plataformas por un período de una a dos semanas para monitorear y comparar resultados.
Esta sección asegura que los datos se migren correctamente y se sincronicen, minimizando los riesgos de inconsistencias y errores en la migración.
Integración Perfecta de BI y Aplicaciones Downstream: Fase 5
El último paso en el proceso de migración es integrar aplicaciones downstream y herramientas BI en el nuevo entorno Databricks Lakehouse. Muchas organizaciones consolidan sus necesidades de data warehousing dentro de Databricks SQL, que no solo proporciona precio y rendimiento excepcionales para analytics sino que también soporta SQL warehouses de alta concurrencia y autoescalado. El motor Photon de Databricks SQL mejora aún más el rendimiento, usando procesamiento vectorizado para consultas rápidas y eficientes.

Después de que los datos y pipelines de transformación están completamente migrados, asegurar la continuidad para aplicaciones downstream y consumidores de datos es esencial. Databricks ha validado integraciones perfectas con herramientas BI ampliamente utilizadas, incluyendo Sigma, Tableau, Power BI y más. Para cambiar workloads de BI sin problemas, redirigir dashboards e informes a menudo es tan simple como actualizar nombres de fuentes de datos a las nuevas tablas de Databricks, especialmente cuando se mantiene la consistencia del esquema. Si los cambios de esquema son necesarios, las tablas y vistas en Databricks pueden ajustarse para coincidir con los formatos esperados para herramientas BI.
Las pruebas son cruciales: comienza con un pequeño conjunto de dashboards para verificar la funcionalidad sin problemas e itera a través del resto según sea necesario.
Conclusiones y Próximos Pasos
Hemos llegado al final de este blog, y la verdad es que es desafiante cubrir un proceso de migración tan amplio de una manera concisa y bien estructurada para los lectores. En próximas publicaciones de blog, profundizaremos en aspectos específicos de la migración para proporcionar insights aún más valiosos para nuestros lectores.
¡Gracias a todos los que leyeron hasta el final del artículo!