Dominando el RAG: Claves para el éxito
Introducción
En el artículo anterior introdujimos los diferentes casos de uso de IA Generativa que se están aplicando y explicamos el potencial de este nuevo paradigma. Ahora nos centraremos en explicar técnicamente qué es lo que se hace y qué desafíos se tienen en estos tipos de proyectos con el fin de que el lector tenga la capacidad de entender cómo es que funcionan, cuáles son los retos que se tienen y sobre todo conocer las diferentes prácticas o técnicas que se pueden aplicar.
La inteligencia artificial se ha democratizado y esto ha permitido que la comunidad y empresas puedan empezar a crear un montón de productos y servicios geniales para el beneficio de todos. Sin embargo, esto también tiene su lado negativo y es que hay una abundancia de información, falta de profesionales especializados y muchos proyectos que no están siendo bien ejecutados en una combinación de vender pruebas de concepto genéricas y falta de know-how en IA Generativa.
¿Cómo insertar conocimiento?
Todos los modelos que tenemos disponibles hoy en día, llámese GPT, Llama, Grok, Gemini, Mistral, etc. y que se utilizan para todos los casos de uso con IA Generativa han sido entrenados hasta una fecha determinada (por ejemplo hasta Septiembre del 2022) y con información públicamente accesible. Entonces, se tienen dos formas de insertar conocimientos en los proyectos de IA Generativa y cubrir este GAP de información:
1. Retrieval Augmented Generation (RAG)
También llamado solo "Retrieval Augmentation", ya que el paso de "Generation" viene después. Consiste en no modificar el modelo, sino añadir contexto al prompt desde una fuente externa. Es como copiarle un texto reciente a ChatGPT para que nos responda sobre él.

2. Fine-Tuning (ajuste fino del modelo)
El segundo, integra conocimiento actualizando los pesos en los modelos mediante un proceso de entrenamiento con la nueva data. A esto se lo conoce como Fine-Tuning. Este proceso es más complejo, costoso, etc., pero puede ser necesario cuando es necesario que el sistema esté muy especializado en un tópico en específico.

Técnicamente se lo "entrena" utilizando prácticas como RLHF (aprendizaje por refuerzo) y optimizadores:
RLHF (Aprendizaje por refuerzo a partir de retroalimentación humana)
a. Por ejemplo, ChatGPT a veces solicita al usuario que seleccione entre dos opciones.Optimizadores (SGD, Adam, RMSprop)
a. Son algoritmos específicos utilizados para minimizar la función de pérdida durante el entrenamiento de un modelo. Todos ellos están basados en el descenso de gradiente. SGD es simple pero efectivo, mientras que Adam y RMSprop pueden ser más intensivos computacionalmente pero a menudo convergen más rápido.
Ejemplo práctico para entender RAG vs. Fine-Tuning
El siguiente ejemplo ayudará a terminar de entender el concepto de RAG y el de Fine-tunning. Imagina que tu jefe te pide que prepares un informe sobre la inteligencia artificial. Ahora, considera estas dos opciones:
La primera es intentar buscar libros, blogs o documentos y a partir de la información recopilada generar el informe. Esto hace un RAG, no ha sido entrenado con esa información, sino que adquiere ese conocimiento consultando fuentes de datos.
La segunda opción es estudiar, incorporar ese conocimiento y volvernos expertos en inteligencia artificial. Somos capaces de crear el informe solicitado con nuestro conocimiento. Esto es el fine-tuning.
¿Cuál es mejor?
Dada la similitud entre la IA y nosotros la respuesta es muy obvia: depende. Para crear un artículo para una empresa que no se dedica a eso, basta con buscar información y dar nuestro mejor esfuerzo (al final, tenemos una capacidad "base" al igual que estos modelos de IA para generar un artículo interesante, por algo ahora los modelos son "inteligentes"). Ahora, en el caso de que trabajemos en una empresa que se especializa en IA, capaz es mejor hacer un Fine-tuning.
Ahora bien, la naturaleza de la comunicación y la información demanda escenarios mixtos. Este blog por ejemplo, es una mezcla de RAG y Fine-Tunning, tengo un conocimiento adquirido en el tópico fruto de mi experiencia pero a la vez he utilizado información de internet para preparar este blog con información actualizada y que añade valor adicional.
Esto nos lleva a otro punto
Es crucial saber cuándo se aplican técnicas: Prompt Engineering, Retrieval-Augmented Generation (RAG), o Fine-Tuning.
Prompt Engineering (*): Esto siempre es necesario cuando se utiliza un LLM para completar una tarea y es ideal cuando el modelo ya ha entrenado con datos relevantes y sólo necesita un poco de guía para extraer y presentar la información.
RAG: La información no está en los datos de entrenamiento originales del modelo, o se necesita información actualizada. Es ideal para situaciones donde la respuesta depende de los datos recientes o conocimiento específico.
Fine Tuning: El modelo debe adaptarse a dominios, lenguajes o estilos específicos insuficientemente cubiertos en su entrenamiento original. Es relevante al existir un cambio importante entre el tipo de datos iniciales del modelo y los que encontrará en la aplicación final.
(*) Prompt: En la inteligencia artificial, especialmente en modelos de lenguaje como GPT, un prompt es una entrada de texto proporcionada por el usuario que inicia o guía la generación de una respuesta por parte del modelo. Actúa como una instrucción o estímulo para que el modelo genere contenido relevante y coherente.

Esquema de Rag Simplificado
Ahora, retomemos el RAG. Un RAG tiene dos "partes". La primera es la ingesta de datos, es decir la adición de conocimiento como comentábamos sin tocar el modelo de LLM a utilizar (podríamos alternar entre cualquiera). La segunda es la recuperación de esa información cuando se realiza una consulta o tarea, y la consecuente generación de la respuesta.
Ingestión de Datos: Un caso de uso común es recopilar grandes cantidades de datos textuales y preparar estos datos para el entrenamiento del modelo. Esto incluye limpiar y normalizar el texto, tokenizar, y aplicar técnicas de ingeniería para transformar los datos de texto en un formato que el modelo de lenguaje pueda entender y aprender.
Consulta de Datos: El proceso de consulta implica realizar preguntas que el modelo responde en base a los datos obtenidos durante su entrenamiento o de fuentes externas. Recuperación es la habilidad para acceder a esa información y la síntesis la capacidad de combinar y reformular esa información para producir una respuesta coherente y a menudo creativa.
En resumen: Se ingesta el documento, se recupera información de acuerdo con la pregunta y luego se genera la respuesta (que se conoce como síntesis).

Los “RAGs” y los problemas con los RAG Naive
Bueno, es importante tener presente que hay diferentes tipos de "RAGs". Todos tienen el mismo propósito, solo que uno más avanzado que otros. En este artículo no vamos a complicar al lector con cada uno de ellos, solo es importante saber que:
Existen técnicas (simples y complejas) que se pueden aplicar para evolucionar los RAG.
La mayoría de proyectos que se ven son "RAG Naive" y aquí nos centraremos en cómo podemos mejorarlos para llevarlos a un próximo nivel "Avanzado".
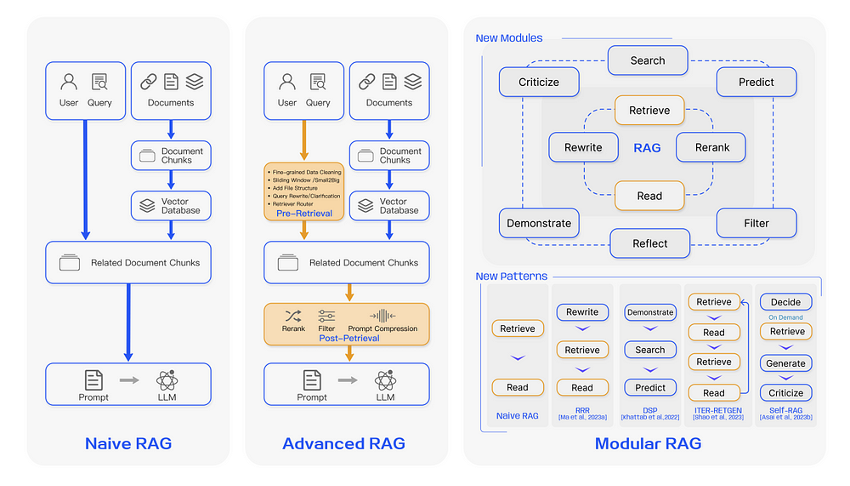
Los RAG Naive pueden tener muchos problemas, que son solucionables si los sistemas fueron construidos e ingestados desde un inicio con un buen framework y conocimiento en materia de IA Generativa. Algunos de los desafíos que tienen los RAG son la mala recuperación (fase de ingestión de datos) y la mala generación de respuesta (fase de consulta de datos y generación respuesta).
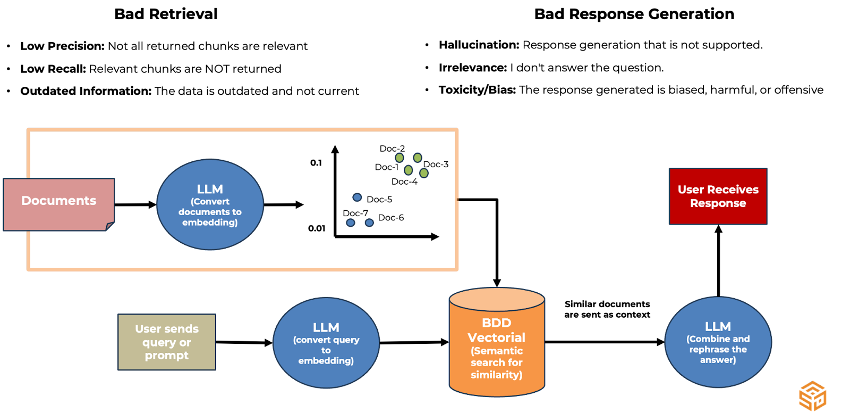
¿Qué podemos hacer?
En pocas palabras, lo que se debe hacer es evaluar. Para ello es importante probar la capacidad del sistema de recuperar información, esto se hace comparando la información devuelta por el sistema con la que "debería" haber recuperado. Así también se deben hacer evaluaciones end-to-end que abarquen también la generación de respuesta.

Por otro lado, existen una infinidad de técnicas que permiten mejorar el rendimiento del sistema. A continuación, explicaremos dos de ellas super simples, que paradójicamente poco se aplican:
Nivel Básico: Tamaño de los Chunks
Cambiar el tamaño de los Chunks (cómo se particionan los documentos cuando se cargan en una base de datos) puede mejorar rápidamente la precisión y la relevancia de la información que se recupera.

Nivel Básico: Filtrar mediante Metadata
Así también, el uso de metadatos ayuda mucho a la recuperación de información con precisión y relevancia. Estos sistemas son inteligentes y capaces de gestionar bastante bien nuestro lenguaje, pero si los ayudamos funcionan mucho mejor. Cuando no se gestionan los metadatos correctamente y la información no se etiqueta correctamente, se pueden generar respuestas incorrectas (imagínense si estamos trabajando con documentos o normas que se actualizan continuamente).
Es más fácil (y económicamente más eficiente a nivel computacional) consultar solo aquellos documentos que se requieren y se evita también generar respuestas con información inadecuada o desactualizada. Cuando esta técnica no se aplica, tenemos el riesgo de que el sistema utilice información que capaz, ya no está vigente para generar la respuesta y la tomemos como válida. Es por esta razón que el procesamiento de datos y la gestión inteligente de los RAGs son clave. La credibilidad depende de su buen uso.

Por qué utilizar Open Source LLM
Finalmente para concluir este blog, queríamos cerrar hablando de los modelos Open Source. En SunnyData tenemos un enfoque agnóstico en este aspecto y desarrollamos soluciones que se puedan adaptar a cualquier tipo de modelo. Al final estamos en una ciencia en continua evolución, pero recomendamos siempre prestar atención a los modelos abiertos, ya que aunque no sean en su versión base mejor a GPT-4 (hoy el líder en el mercado en abril del año 2024), bien utilizados se adaptan mejor al negocio cuando el negocio requiere de ese grado de especialización.

Algunos de los beneficios:
Transparencia: Una mejor comprensión de cómo funcionan, su arquitectura y los datos de capacitación utilizados.
Fine-Tunning: Permiten un ajuste fino, añadir datos específicos para cada caso de uso.
Comunidad: Se benefician de la contribución de las personas con diferentes perspectivas.
Databricks ha lanzado la semana pasada un nuevo modelo (DBRX) propio que define un nuevo estado del arte de la comunidad de modelos de código abierto y supera en rendimiento a los anteriores. En SunnyData dedicaremos un blog a esta nueva tecnología una vez lo probemos lo suficiente.

Conclusiones
Esperamos que este blog haya sido del agrado del lector, pero estamos convencidos de que ayudará un montón a entender acerca de RAG, Fine-Tuning, cómo hacer mejores proyectos y sobre todo a democratizar el conocimiento. ¡Los esperamos la próxima semana con más contenido! ¡Gracias!